AI/ML●●Solid
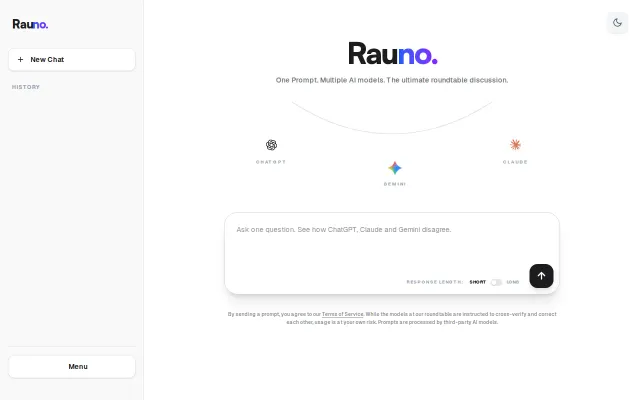
A multi-model interface where LLMs debate with each other
Orchestrates real-time skepticism between models to catch hallucinations before you see them.
Solve My ProblemShip It
capibara13
491mo ago

Multi-model debate orchestration is clever, but 'audit with AI' is crowded territory.
Smart contract developers and protocol teams
ConsenSys Diligence · Trail of Bits · SlowMist
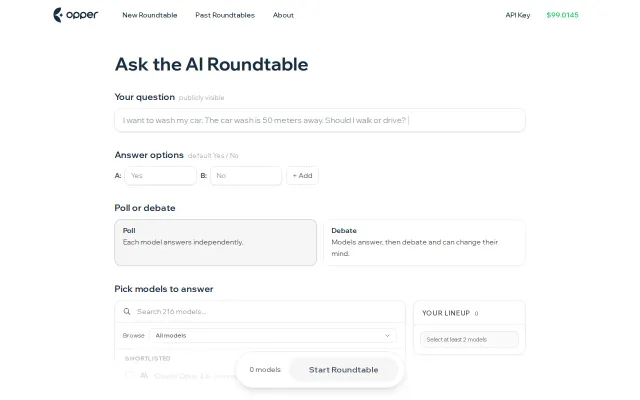
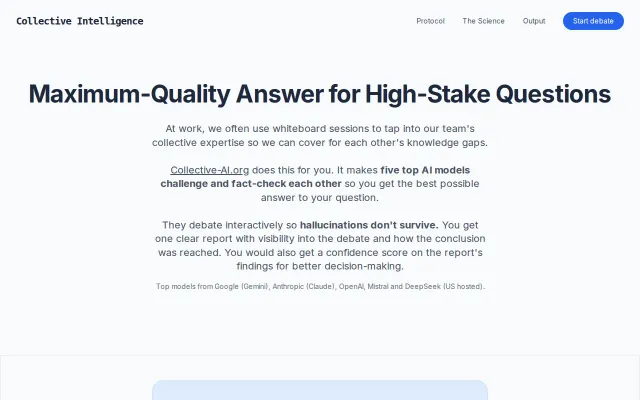
harden runs 5 frontier models (Claude, GPT-4o, Gemini, Mistral, DeepSeek) in parallel on the same input. They analyze independently, then cross-examine each other's findings. A coordinator synthesizes the debate into consensus findings and produces a fixed version.
The key insight: no single model finds more than ~72% of issues. The union of all five hits ~94%. After cross-examination (where models must defend findings against skeptical peers), accuracy rises to ~97% and false positives drop ~60%.
How it works: - Round 1: All 5 models audit independently (no groupthink) - Debate: Each model reviews others' findings, provides evidence for/against - Consolidation: Only findings that survive cross-examination make the report - Fix: Coordinator produces a revised version addressing consensus issues - Round 2+: Same pipeline runs on the fixed version, catching fix-introduced bugs
Started with smart contract audits but it generalizes — legal docs, resumes, fact-checking, financial analysis all benefit from multi-model consensus.Free tier available.
Built with React, Node, SSE streaming for real-time progress. The debate transcripts are the most interesting part — watching GPT-4o argue with Claude about whether a reentrancy vector is exploitable is genuinely useful.
Blog with more details on the multi-model approach: https://harden.center/blog
Orchestrates real-time skepticism between models to catch hallucinations before you see them.
Debate mode where models change minds is novel, but model comparison tools already exist.
Kahneman's adversarial collaboration applied to multi-model debates, not just model ensemble.
Multi-agent code review with internal debate beats single-pass LLM tools.
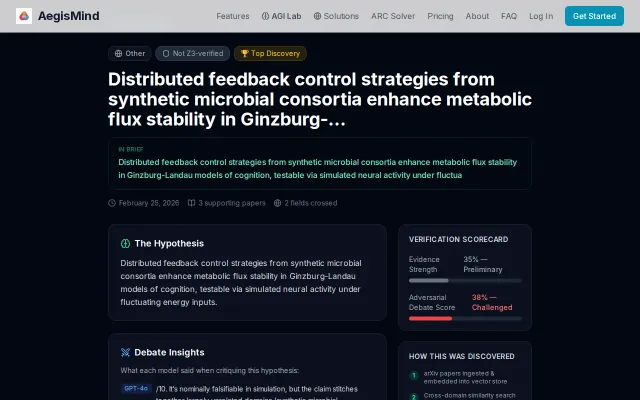
Multi-model debate on research hypotheses, but Z3 can't verify the actual claims.
Multi-agent code review plugin when CodeRabbit and Cursor already do this.