Developer Tools○Pass
CVD Tool – Image Compression Algorithm (13MB to 10KB)"
99.9% compression claims need peer review—zero stars, one commit, no standard benchmarks.
mohamedtrigui5
222mo ago
Mixed-precision quantization that somehow improves accuracy through regularization.
Machine learning engineers, model optimization researchers, edge AI developers
AWQ · GPTQ · Qwen3.5-4B quantization efforts
Recently, there was a discussion here about Qwen3.5 fine-tuning where it was noted that QLoRA/4-bit quantization is "not recommended" due to severe accuracy degradation. I wanted to challenge this limitation.
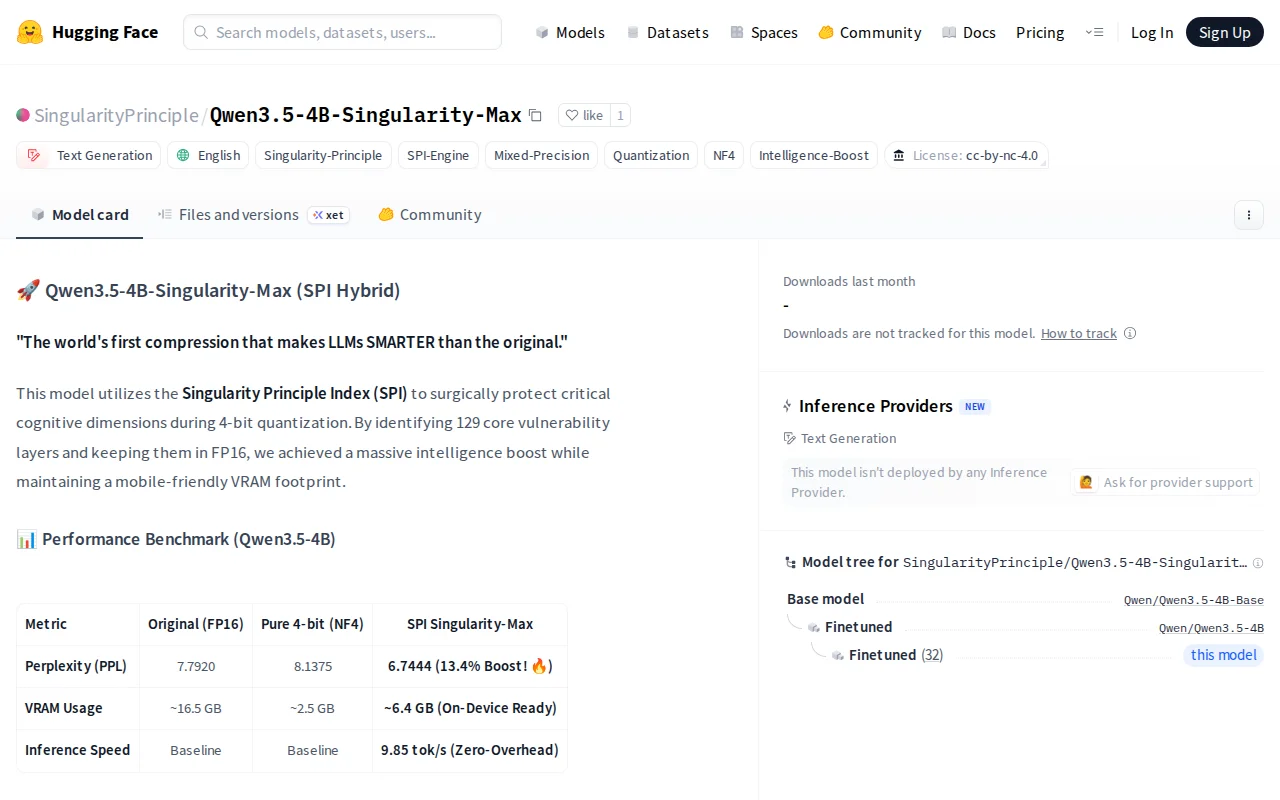
I developed a mixed-precision hybrid model (*Qwen3.5-4B-Singularity-Max*) that uses ~6.4GB of VRAM but actually achieves a lower Perplexity (6.74) than the original FP16 baseline (7.79).
*How is this possible? (The Noise-Canceling Effect)* Instead of uniform quantization, I applied a mathematical framework called the *Singularity Principle Index (SPI)*. By analyzing the power-law spectral decay (alpha) of weight matrices, the engine identified exactly 129 "critical cognitive layers" out of the entire architecture.
We kept these 129 layers (approx. 3.9GB) in crisp FP16 and aggressively quantized the rest (90%) to 4-bit NF4. The 4-bit quantization acted as a massive Regularization filter—stripping away overfitting artifacts (noise)—while the FP16 layers protected the core logic.
*The Results (Apples-to-Apples):* * *Perplexity:* 7.79 (FP16) -> 8.13 (Pure 4-bit) -> *6.74 (SPI Hybrid, 13.4% Boost)* * *VRAM:* ~16 GB -> *~6.4 GB* (Fits easily on consumer GPUs/Edge devices) * *Inference Speed:* *9.85 tokens/sec* on a free Kaggle T4 (Zero dequantization overhead due to `SafeFP16Linear` physical isolation).
You don't need any calibration data. It's a zero-shot surgical weight refinement.
* Academic Foundation & Citation* The theoretical framework governing the Spectral Compactness initialization and Trace-norm Regularization utilized in this model is fully detailed in our recent academic preprint: * *Paper Title:* Spectral Compactness Ensures Robustness in Low-Precision Neural Networks * *DOI:* 10.21203/rs.3.rs-8880704/v1 (https://doi.org/10.21203/rs.3.rs-8880704/v1)
(If you utilize this model or the Spectral-Compactness-Aware Mixed Precision methodology in your research or applications, please cite the paper above.)
*Resources:* * *Model & 1-Click Inference Script:* https://huggingface.co/SingularityPrinciple/Qwen3.5-4B-Singu...
I’d love to hear your thoughts, especially from those working on On-Device/Edge AI deployment. Does this change the calculus for running local LLMs?
99.9% compression claims need peer review—zero stars, one commit, no standard benchmarks.
Runs 405B model compression on a single 32GB GPU when others need enterprise clusters.
Data-oblivious quantization beats Product Quantization on online updates.
SHA-256 verifiable manifests prove lossless compression mathematically, not just statistically.
Zero-training vector quantization that's 600x faster than Product Quantization.
Replaces Tensor Cores with LUTs and bitwise ops for 3-bit edge inference.