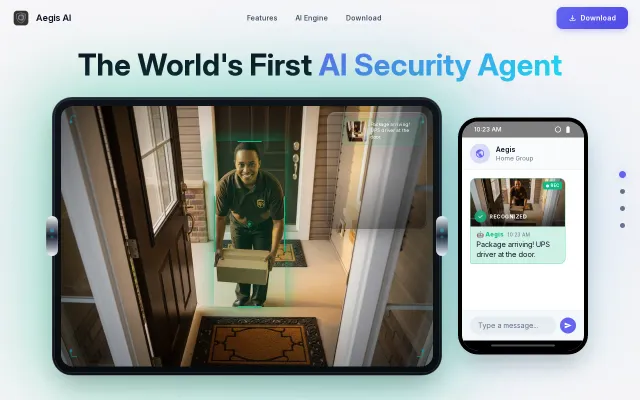
Roz is an open-source, Python-based pipeline that captures a webcam feed, detects motion, sends the frames to a local Vision LLM to analyze the scene, and then uses text-to-speech to audibly announce any meaningful changes.
The Backstory:
I heard an ad for Google’s Home Premium Advanced service, which claims to analyze your Nest doorbell images and describe what it sees. I thought that sounded cool, but I didn't want to pay $20/month for it or send my camera feeds to the cloud. I wanted to see if I could build a localized, subscription-free version myself.I 3D-printed a head-shaped enclosure to house the camera and speaker.
How it works:
1. Stage 1 (Lightweight): Python app runs on a low-power device (like a Raspberry Pi 4) using OpenCV to perform basic frame-differencing. This takes barely any compute.
2. Stage 2 (Heavy): When motion crosses a configurable threshold, the frames are sent to a vision-capable LLM. (I'm using Qwen3.5 35B hosted on a separate PC with an RTX 3090, but any OpenAI-compatible endpoint like vLLM or llama.cpp works).
3. Stage 3 (Audio): The LLM compares the current scene to the previous baseline context. If there is a meaningful change, the LLM generates a text description of what it sees, which is then read out loud locally via Piper TTS.
Hardware & trying it out:
Since this relies on physical hardware, the easiest way to see it in action is the demo video in the README (make sure to unmute the audio).
The hardest part so far is the subjectivity of what constitutes a "meaningful change". I'm still tweaking the prompt rules to hit the sweet spot between "announce everything" and "miss important events".