Security●●Solid
PromptSonar – Static analysis for LLM prompt security
Static scanner catches prompt injections in code before runtime, unlike runtime guards.
Solve My ProblemShip It
meghal86
103mo ago
🛡️ Promptinel is a deterministic security scanner for machine-interpreted natural language that treats prompts as executable artifacts.
Deterministic prompt linter flags injection, exfiltration, obfuscation before LLM runs—treats prompts as executable code.
DevOps engineers, prompt library maintainers, teams shipping LLM agents or multi-user prompt repositories.
Bandit (Python linter) · Semgrep · Gitleaks
Promptinel is a security scanner for prompts. I think the world needs something like this, because prompts are basically executable artifacts and we need to treat them as such. I want to identify as many bad things as I can before a prompt gets anywhere near runtime. Especially when supplying a common prompt repository for friends or colleagues, or when downloading skills from the internet. You can read more about my motivation in the project's readme: https://github.com/CunningFatalist/promptinel?tab=readme-ov-...
Promptinel finds various attack patterns in prompts, for example:
- prompt override and role spoofing patterns - download-and-execute chains - template execution and network fetch behavior - secret exfiltration intent - invisible Unicode and obfuscation tricks - local sensitive file references
I'm really looking forward to feedback from people, who have built linters or security scanners before. Or just feedback from Go people, really. I'm mainly a PHP and TypeScript dev and use Go in my free time, because I find it fun and love the philosophy behind it.
Static scanner catches prompt injections in code before runtime, unlike runtime guards.
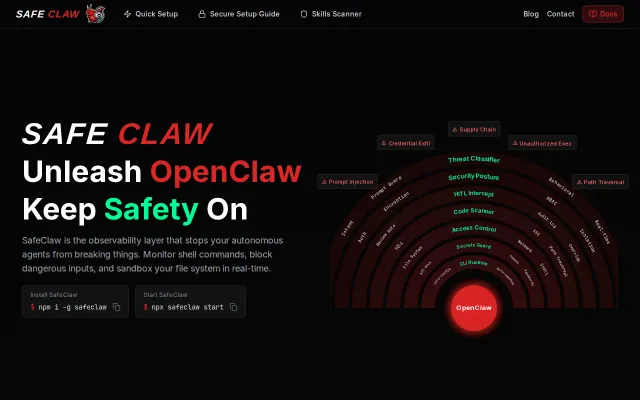
It actually looks for the weird stuff that trips up LLM agents — invisible Unicode, bidi overrides, embedded curl|bash one-liners, exfil links — and pairs a static skill scanner with a real-time interception flow that forces human approvals. The CLI-first approach (npx safeclaw start) plus Socket.IO alerts and per-command allow/deny decisions show practical thinking about developer workflows; I want to see model/false-positive metrics and enterprise integration docs next.
Semgrep for AI agents—138 rules, offline, catches obfuscated attacks other scanners miss.
Purpose-built LLM security linter covers OWASP Top 10, but static analysis has inherent blind spots.
Prompt CVE tracking is clever, but LangSmith and Arize already cover this ground.
Docker sandbox execution catches runtime threats static analysis alone misses.