AI/ML●Mid
Continual Learning with .md
Scrappy v1 with dangerous setup flags and zero stars on GitHub.
Niche GemBold Bet
wenhan_zhou
34342mo ago
MindSwarm Core - Open Source AI Agent Orchestration Platform
Filesystem-dwelling AI agents with bio-feedback drives in a crowded agent space.
AI researchers, developers experimenting with autonomous agents and emergent behavior
AutoGen · CrewAI · LangGraph
I played around with one last year and it was promising, but I assume there must be others?
I'm talking about classic A-Life stuff like we did back at Creature Labs just with the Neural Network replaced with an LLM.
My approach last year, was to put the 'Cybers' (my name for them) inside a file system and then gave them bio-feedback fed into their context for things like boredom and community engagement. Context size was another stat they actively 'saw' and run python programs to mutate there own context and move and interact with the filesystem world.
They run continuously loops, so effectively something like RLM, writing interpreted python programs to change their world and mutate there own context.
I could get about 3 working simultaneously before cost/speed came to much to stand.
Main issue was memory and task repetition, as they would get stuck doing the same things forgetting they had done it already. The other being cost, running 3-4 LLMs in a continuous loop for days on end, added up. I used subscription services with rate limiting.
Biggest surprise was one starting writing a book on its experiences completely unprompted, I provided them a bunch of books from Project Gutenberg and it was one of the community jobs to read and write notes about them. One decided to write its own based on its experience as a Cyber.
Haven't touched it in a while, so wondering who else has tried experiments like this?
Scrappy v1 with dangerous setup flags and zero stars on GitHub.
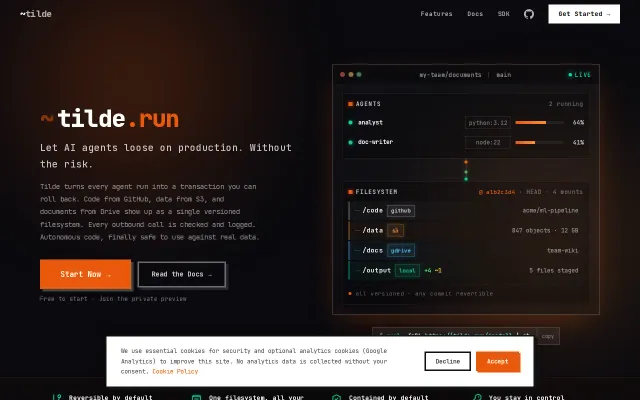
Roll back any agent run like a Git commit with a single command.
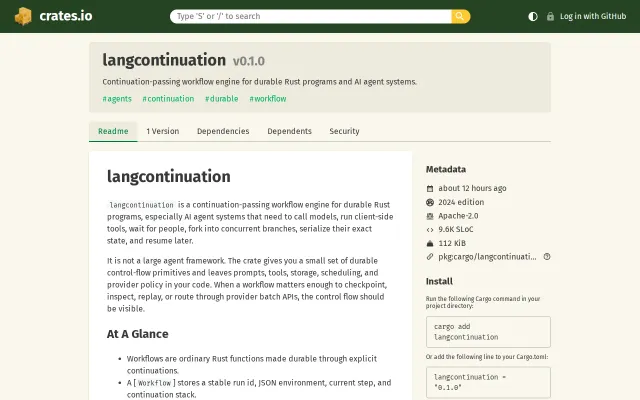
Continuation-passing durability with live/batch switching, but LangGraph and Temporal already own this space.
Google Drive CLI for agents, but rclone and existing integrations already cover this.
Putting the memory layer on-disk as a .afs/ tree is a gutsy, practical move — you get searchable JSON, FTS5 for text queries, HNSW vectors for similarity, and msgpack edges for relationships without running a separate DB service. It feels like a thoughtful toolkit for agents that must persist thinking artifacts (observations → reflections → knowledge), though I want to see details on concurrency, index portability, and how this performs at scale before betting production workloads on it.
LLM cost optimizer, but Anthropic's batch API and local quantization solve this cheaper.