AI/ML●●●Banger
LOAB – benchmarking AI process fidelity in lending
Scores AI agents on process fidelity, not just outcomes—catches KYC skips that other benchmarks miss.
Big BrainSolve My ProblemZero to One
shubh-chat
103mo ago
LOAB: A benchmark for evaluating LLM agents on end-to-end mortgage lending operations under real regulatory constraints.
Frontier models hit 67-75% outcome accuracy but only 25-42% on process compliance.
AI developers building agents for regulated industries, compliance teams
GAIA · AgentBench · SWE-bench
Scores AI agents on process fidelity, not just outcomes—catches KYC skips that other benchmarks miss.
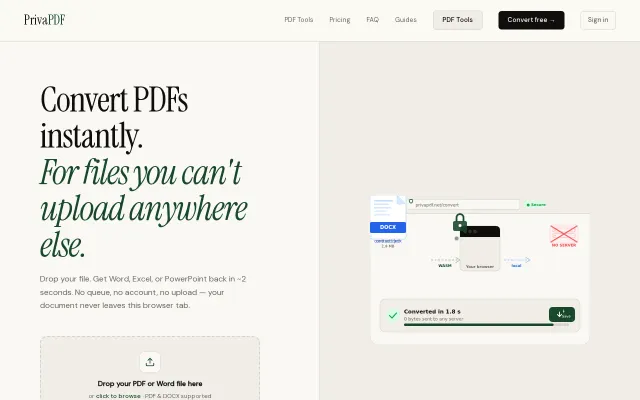
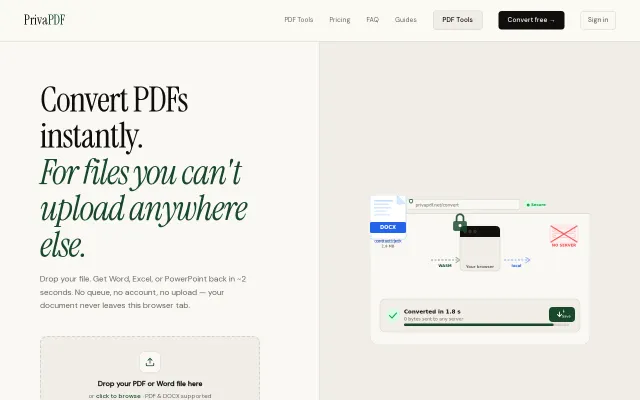
Client-side WASM conversion is nice, but CyberChef and pdf2go already do this.
Hardware post-mortem proving you don't need to open-source everything to be repair-friendly.
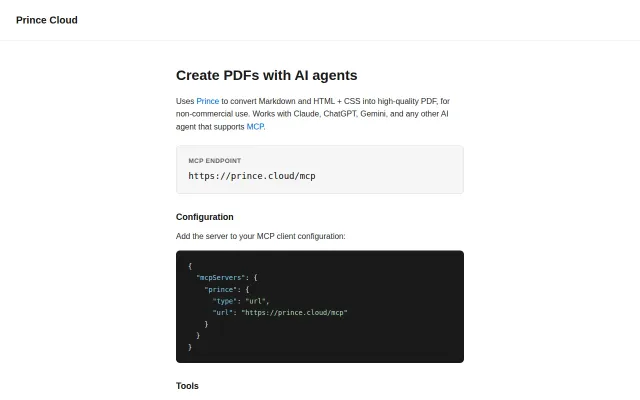
Prince XML typesetting as an MCP tool for Claude and GPT agents.
WASM-based conversion keeps sensitive PDFs on-device when cloud tools aren't an option.
Visual PDF workflow builder, but Zapier and PDF.co already dominate this space.