AI/ML●●Solid
Shard-based scheduling for 100x more fine-tuning experiments on 4 GPUs
Shard-based scheduling cuts GPU wait time, though Ray Tune offers similar early stopping.
Big BrainSolve My Problem
kamranrapidfire
103mo ago
High-performance Rust extensions for Axolotl (no OOM for large datasets) - drop-in acceleration for existing installations.
77x faster data loading but only helps if you're already using Axolotl specifically.
ML engineers fine-tuning large language models
Polars · Petastorm · WebDataset
The problem: Python data pipelines become the bottleneck when fine-tuning large models. Your GPUs sit idle waiting for data.
The solution: Drop-in Rust acceleration. One import line, zero config changes.
Results on 50k rows: - Streaming data loading: 0.009s vs 0.724s (77x faster) - Parallel SHA256 hashing: 0.027s vs 0.052s (1.9x faster)
Works with Parquet, Arrow, JSON, JSONL, CSV. Supports compression. Cross-platform.
Usage:
import fast_axolotl import axolotl # now accelerated pip install fast-axolotl
Built with PyO3 and maturin. MIT licensed. Happy to answer questions about the Rust/Python interop or benchmark methodology.
Shard-based scheduling cuts GPU wait time, though Ray Tune offers similar early stopping.
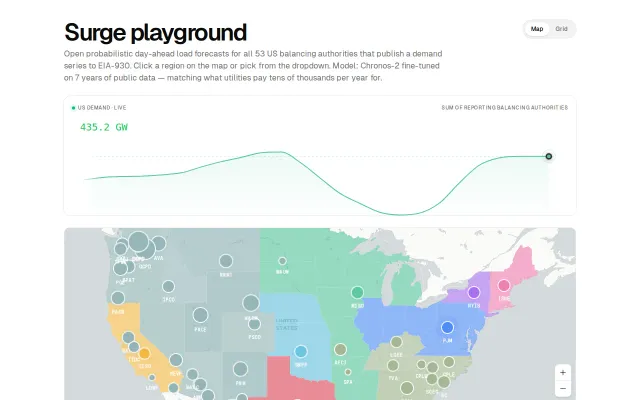
Beats utility forecasts on 6 of 7 RTOs using only public EIA data and open models.
Galaxy classification model, but model card has mostly empty fields.
Eval-synthesize-train loop automates custom model development better than manual fine-tuning.
Fine-tuned Qwen 30B that prioritizes output diversity over convergent accuracy.
Detachable PEFT modules that version independently, unlike LoRA's weight-coupled adapters.