Developer Tools●●●Banger
Cheddar-bench – unsupervised benchmark for coding agents
Unsupervised bug benchmark using agents as both attackers and defenders—novel scoring methodology.
Big BrainWizardryShip It
przadka
903mo ago
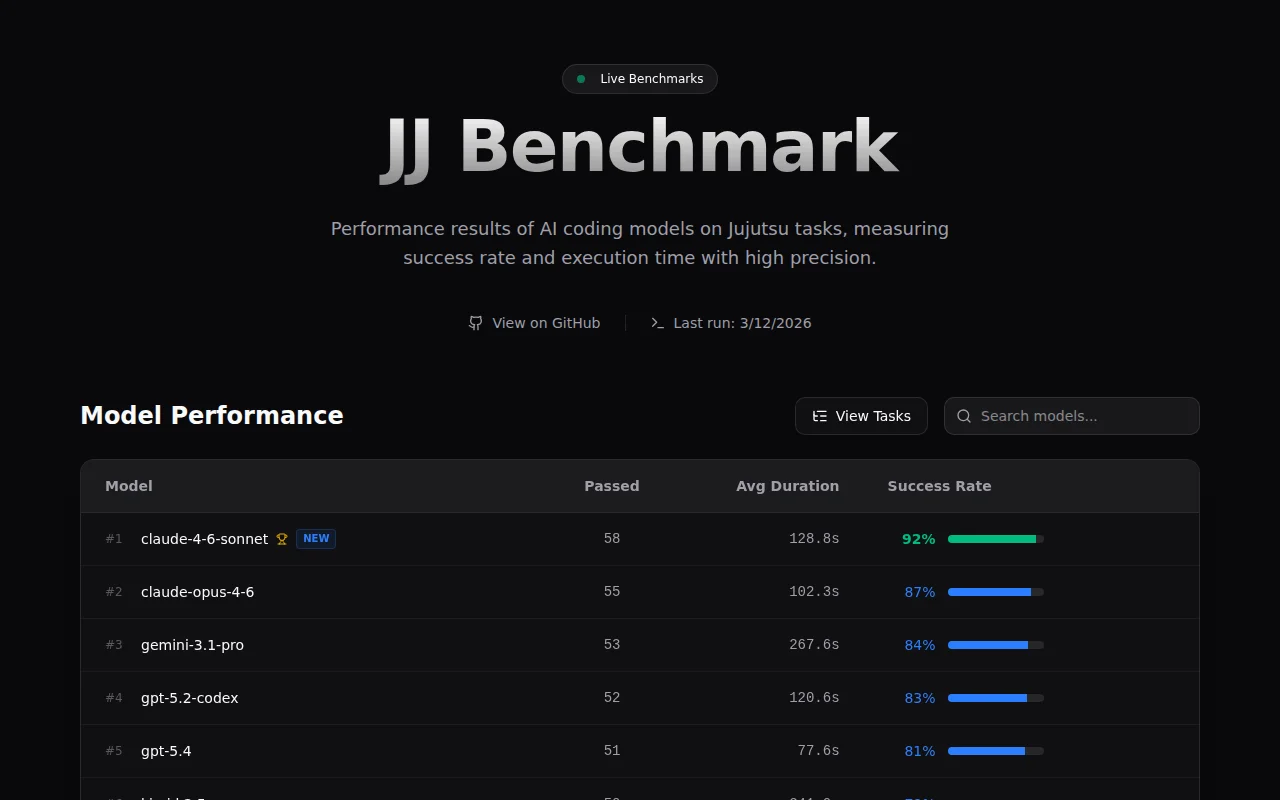
AI benchmarking for jj CLI when LMSys and HuggingFace already dominate the space.
AI developers, version control enthusiasts, jj users
LMSys Chatbot Arena · HuggingFace Open LLM Leaderboard · HumanEval
We decided to build this simply because we find Jujutsu (jj) really interesting, and many folks on our team have started trying it out recently. Since it introduces a very different workflow compared to traditional Git, we thought it would be a fun challenge to see how well current AI coding agents can actually use it.
To build this, we created a semi-automated pipeline. We used AI to research the official Jujutsu documentation and websites, which then helped us bootstrap a dataset of 63 distinct evaluation tasks. Each task includes instructions, bootstrap scripts, and tests. We then ran the evaluations using the Harbor framework and our Pochi agent.
Some interesting insights from our initial leaderboard:
Claude 4.6 Sonnet is the clear winner: It achieved a 92% success rate (passing 58/63 tasks), beating out Opus and OpenAI's top models. It seems exceptionally good at parsing the novel CLI rules of jj. The Speed vs. Accuracy Trade-off: While GPT-5.4 sits at #5 with an 81% success rate, it is incredibly fast, averaging just 77.6s per task. In contrast, Gemini-3.1-pro achieved 84% but took over 3x as long (267.6s average). Open Weights / Regional Models are competitive: Models like Kimi-k2.5 (79%) put up a very respectable fight on a relatively niche tool. The benchmark isn't completely solved yet, but the fact that top models can successfully navigate a relatively new version control system by reasoning through the tasks is pretty exciting.
If there are specific jj edge cases you think we should add to the dataset, feel free to open up a PR!
Unsupervised bug benchmark using agents as both attackers and defenders—novel scoring methodology.
Finally brings visual diffing to the terminal-native Jujutsu workflow.
Git-native prompt versioning with Crucible evaluation, but only 1 star on GitHub.
Deterministic agent benchmarking with strict validation—unlike SWE-Bench, measures whether agents actually operate.
Exposes how current AI coding benchmarks inflate success rates by 20%.
Interactive DuckDB-WASM benchmark beats static leaderboards for agentic SQL eval.