Developer Tools●●Solid
Lumen–free Real-time LLM token and cost monitor
Wire-protocol proxy means zero code changes to existing LLM clients.
Solve My ProblemSlick
Datagrout
201d ago
Tokenlens is an open-source AI prompt and agent workflow analyzer that finds token waste, repeated context, and prompt caching opportunities to reduce LLM cost and latency.
Local budget caps block requests before provider dashboards even update the bill.
Developers building LLM applications
Helicone · LangSmith · LiteLLM
It's a local HTTP proxy that sits between your app and the AI provider (Anthropic, OpenAI, Google). Every request flows through it, and it records token usage, cost, cache hit rates, latency — everything. Then there's a dashboard to visualize it all.
What makes it different from just checking your provider dashboard:
It's real-time (WebSocket live feed of every call as it happens) It works across all three major providers in one view It runs 100% locally — your prompts never leave your machine It has budget caps that actually block requests before you overspend It identifies optimization opportunities (cache misses, model downgrades, repeated prompts) Tech stack: Python, FastAPI, SQLite, vanilla JS. No React, no build step, no external dependencies beyond pip. The whole thing is ~3K lines of Python.
Interesting technical decisions:
The proxy captures streaming responses without buffering — it tees the byte stream so the client sees zero added latency Cost calculation uses a built-in pricing table with override support (providers change rates constantly) There's a Prometheus /metrics endpoint so you can plug it into existing monitoring Cacheability analysis uses diff-based detection across multiple API calls to identify what's actually static vs dynamic in your prompts Limitations I'm honest about:
The cacheability scorer is heuristic-based — solid for multi-call traces (~85% accurate), rougher for single prompts (~65%) Token counting uses cl100k_base for everything, which drifts ~10% for non-OpenAI models Three features (smart routing, scheduled reports, multi-user auth) are on the roadmap but not shipped yet Would love feedback, especially from anyone managing LLM costs at scale.
Wire-protocol proxy means zero code changes to existing LLM clients.
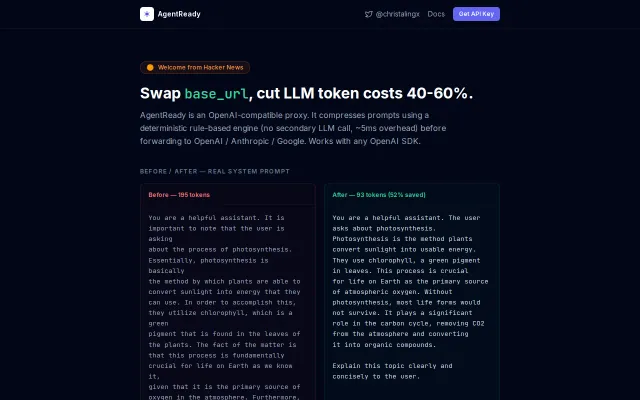
Drop-in proxy that cuts GPT token costs 40-60% without changing app code.
OpenAI-compatible proxy with PII masking and token budgets—but LiteLLM, Helicone already do this.
Drop-in Claude API proxy with real-time cost dashboard—but Anthropic's own billing UI exists.
Proxying every LLM call to log tokens is the right kind of blunt instrument — you get per-developer, per-model cost telemetry immediately. Smart routing and the built-in semantic cache (claims 45–80% savings) are the most useful ideas here, but the default SQLite backend and admin/admin creds scream MVP rather than production-ready scale.
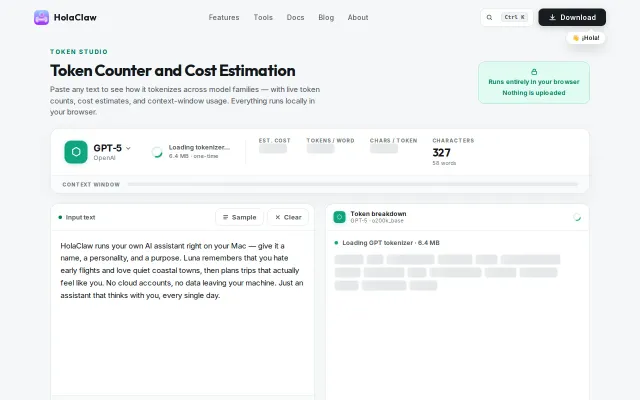
Local tokenizer execution beats sending text to external counters.