Infrastructure●●Solid
ARouter – drop-in OpenAI/Anthropic proxy that cuts cost and fails over
OpenAI SDK calls Claude through one proxy with conformance-tested wire translation.
Ship ItBig Brain
sricola
211mo ago
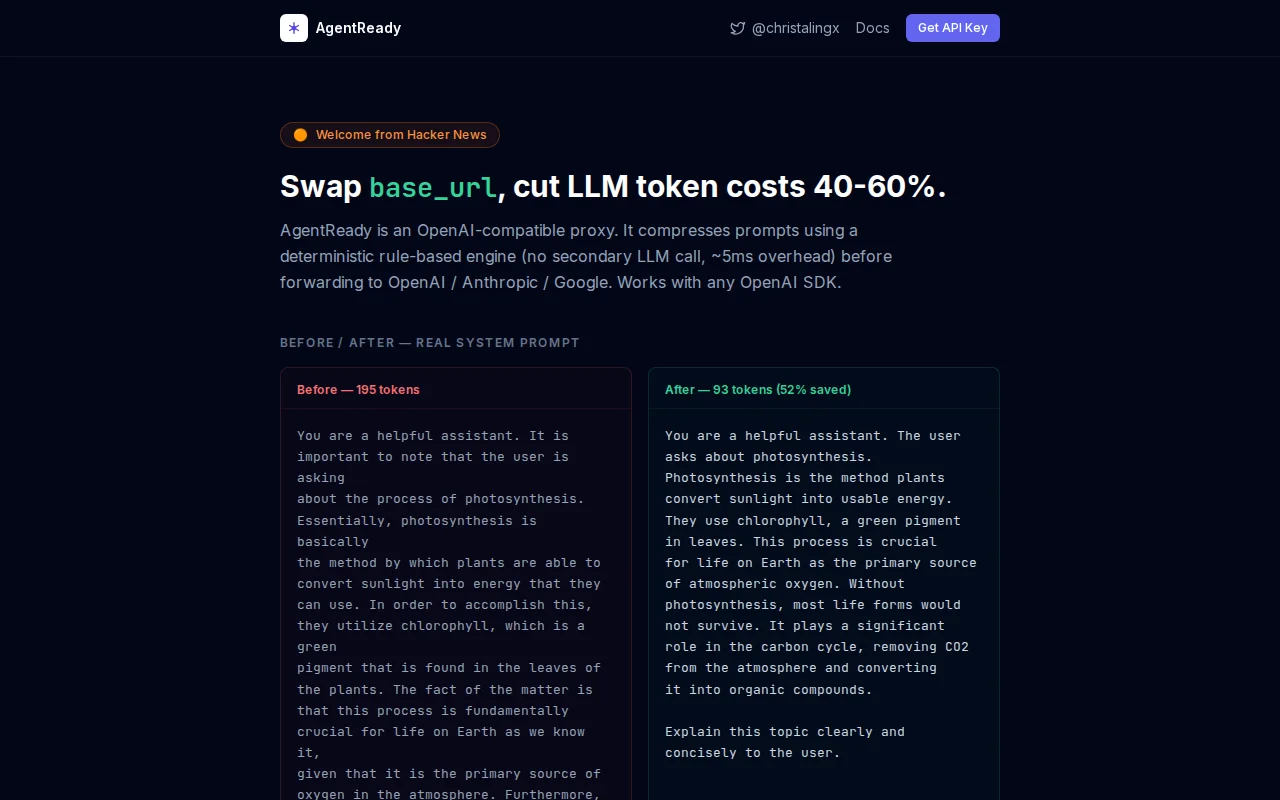
Drop-in proxy that cuts GPT token costs 40-60% without changing app code.
Engineers shipping LLM-powered applications with per-token billing concerns
Langsmith · LlamaIndex · Helicone
OpenAI SDK calls Claude through one proxy with conformance-tested wire translation.
If you're burning through Claude/OpenAI credits, this is a low-friction stopgap: it classifies prompts in ~10ms and routes trivial tasks to cheaper/local models while reserving premium APIs for complex work. The agentic-task detection, reasoning-aware routing, session pinning and context-window fallback are practical touches that avoid mid-thread model bouncing and 429 failures. It isn't reinventing the space (OpenRouter and others exist), but it's focused on real-world cost tradeoffs and drop-in compatibility.
Local budget caps block requests before provider dashboards even update the bill.
Wire-protocol proxy means zero code changes to existing LLM clients.
Prompt compression API cuts token bills 40-60%, integrates in two lines.
Semantic caching for LLMs when LiteLLM and Helicone already do this.