Other○Pass

Csrct – The Bottleneck Is the Strategy
Long-form geopolitical essay that belongs on a blog, not a software showcase.
MADEinPARIS
101mo ago
High-throughput long-context LLMs. Scaling context via RandNLA and massive vocab capacity through MAXIS Loss and Fisher-SVD.
Claims 17.5x training speedup with Matryoshka embeddings for native RAG.
ML researchers and engineers training long-context models
Mamba · Linear Attention · RetNet
Long-form geopolitical essay that belongs on a blog, not a software showcase.
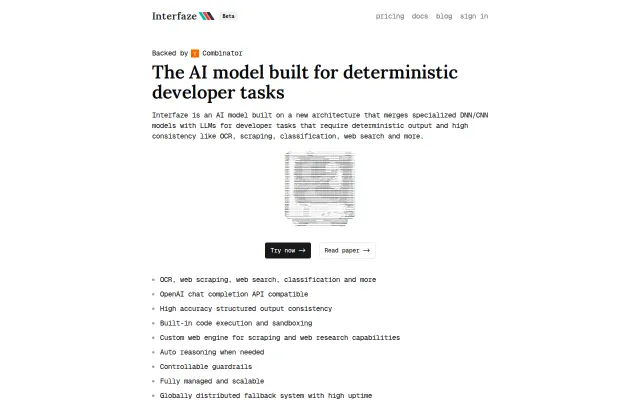
Claims new DNN+LLM architecture for deterministic OCR and scraping tasks.
Another transformer-from-scratch tutorial in a saturated space.
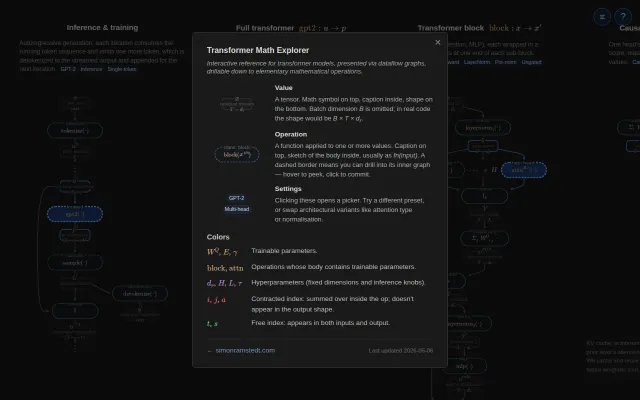
Best interactive transformer visualizer I've seen — finally explains tensor shapes clearly.
Ghost Logit math bypasses 262k vocab OOM without materializing full matrices.