AI/ML●●Solid
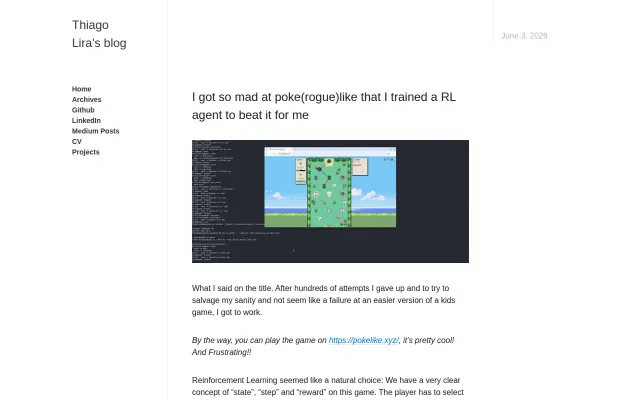
A 178K Neural Net that beats Pokémon Roguelike
178K neural net beats Pokémon roguelike with clever 1386-dim state encoding.
Rabbit HoleNiche GemCozy
farcaster
301mo ago
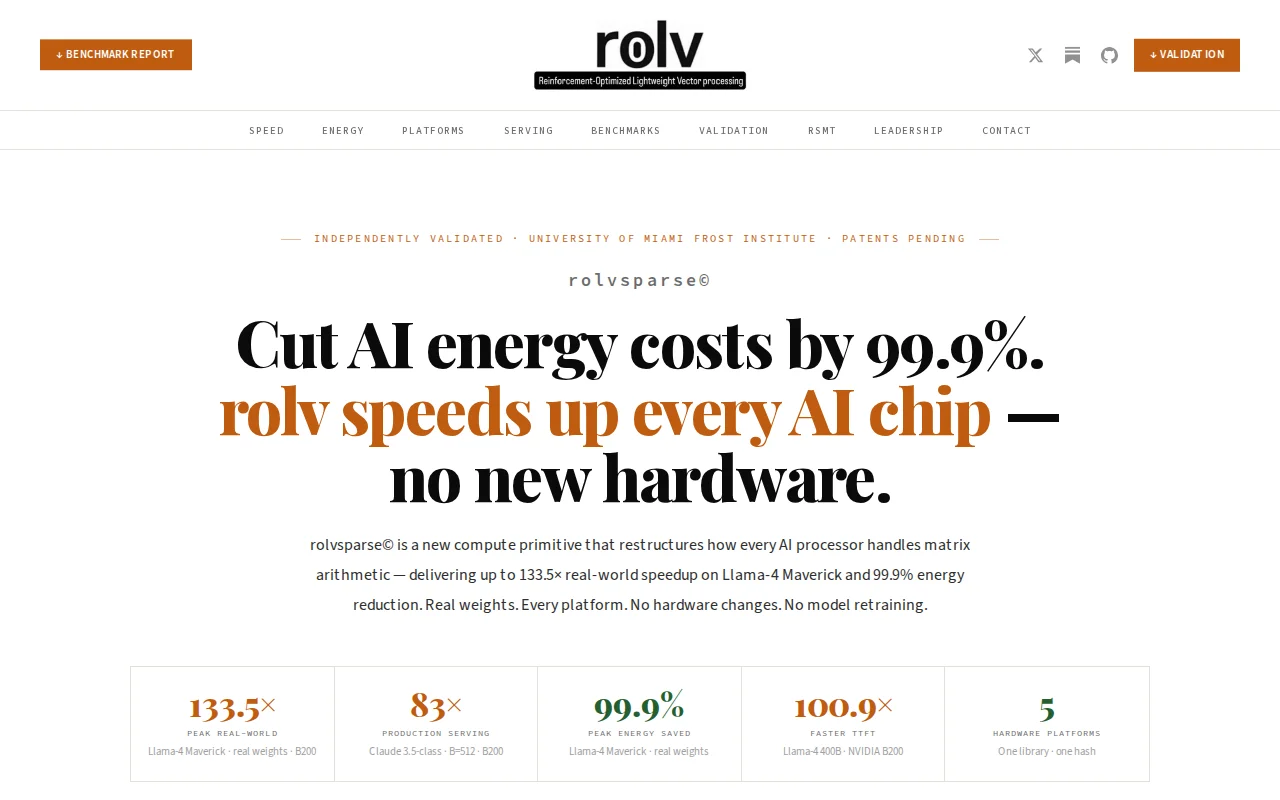
133.5× speedup with identical SHA-256 hash across NVIDIA, AMD, Intel, Apple Silicon.
ML engineers, AI infrastructure teams, GPU optimization specialists
vLLM · TensorRT-LLM · DeepSpeed
Mistral-7B real weights, 0% sparsity (fully dense): 127× vs CPU dense, 474× vs CPU sparse, 0.7ms first token vs 49.4ms sparse, 99.2% less energy Llama-2-7B real weights, 0% sparsity: 59× vs dense, 228× vs sparse, 0.8ms first token
On NVIDIA B200 with real HuggingFace weights:
Llama-4 Maverick 400B: 133.5× faster, 99.9% less energy, 52× faster first token DeepSeek-R1 (256 experts): 78.9× faster, 98.7% less energy
The canonical SHA-256 hash appears identically across NVIDIA, AMD, Google TPU, Intel, and Apple Silicon — same math, different silicon, same answer. Independently validated by University of Miami Frost Institute. Open verifier at rolv.ai — runs on any hardware, generates your own baseline hash. No IP in the verifier. Happy to answer technical questions about how it works.
178K neural net beats Pokémon roguelike with clever 1386-dim state encoding.
Gives AI agents surgical Git control—solves destructive workarounds in autonomous coding workflows.
Interesting alignment hypothesis but demo scripts aren't evidence of effectiveness.
Pure Vulkan compute enables LLMs inside game loops without CUDA lock-in.
LLM-guided structural preprocessing beats xz -9e on 103/103 Alpine binaries tested.
SAE feature explorer, but limited to tweet analysis with unclear research value.