AI/ML●●Solid
SparseLab–real sparse training(CSR+custom kernel) in PyTorch, CPU-first
Custom CPU kernels for sparse training when everyone else chases GPU.
Niche GemBig Brain
DARSHANFOFADIYA
111mo ago
metal collective communication library (pytorch DDP)
Two MacBooks syncing gradients over Thunderbolt — slower than single-GPU but it works.
ML researchers with multiple Macs experimenting with distributed training
NCCL · Gloo · PyTorch Distributed
Custom CPU kernels for sparse training when everyone else chases GPU.
Automates the painful torch.compile and mixed-precision tuning loop with measured 3x speedups.
TPU training wrapper built on torchprime; solves a real problem but torchprime already exists.
Infers layer shapes from connections and exports standard PyTorch scripts.
Per-agent PPO runtime with tensor-first simulation state is genuinely clever architecture.
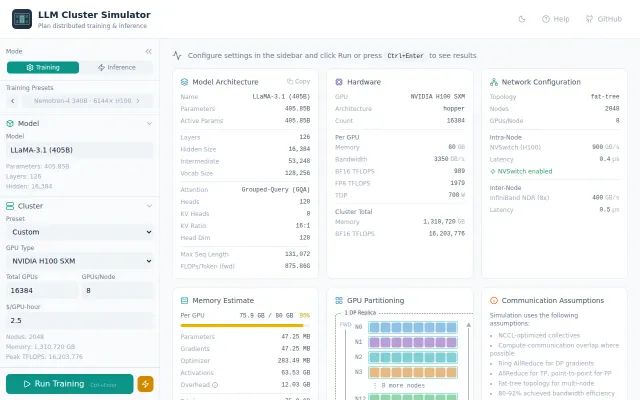
Estimates LLM training MFU, memory, timeline across 70 models and parallelism strategies—genuinely useful before GPUs commit.