Data●●Solid
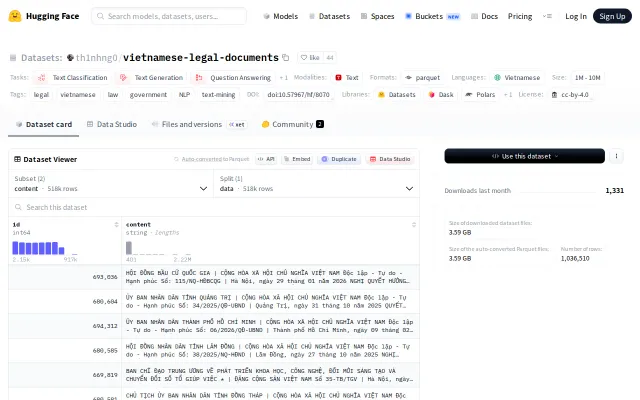
518K Vietnamese legal documents (1924–2026)
518k Vietnamese legal documents fill a massive gap in Southeast Asian NLP datasets.
Niche GemDark Horse
th1nhng0
302mo ago
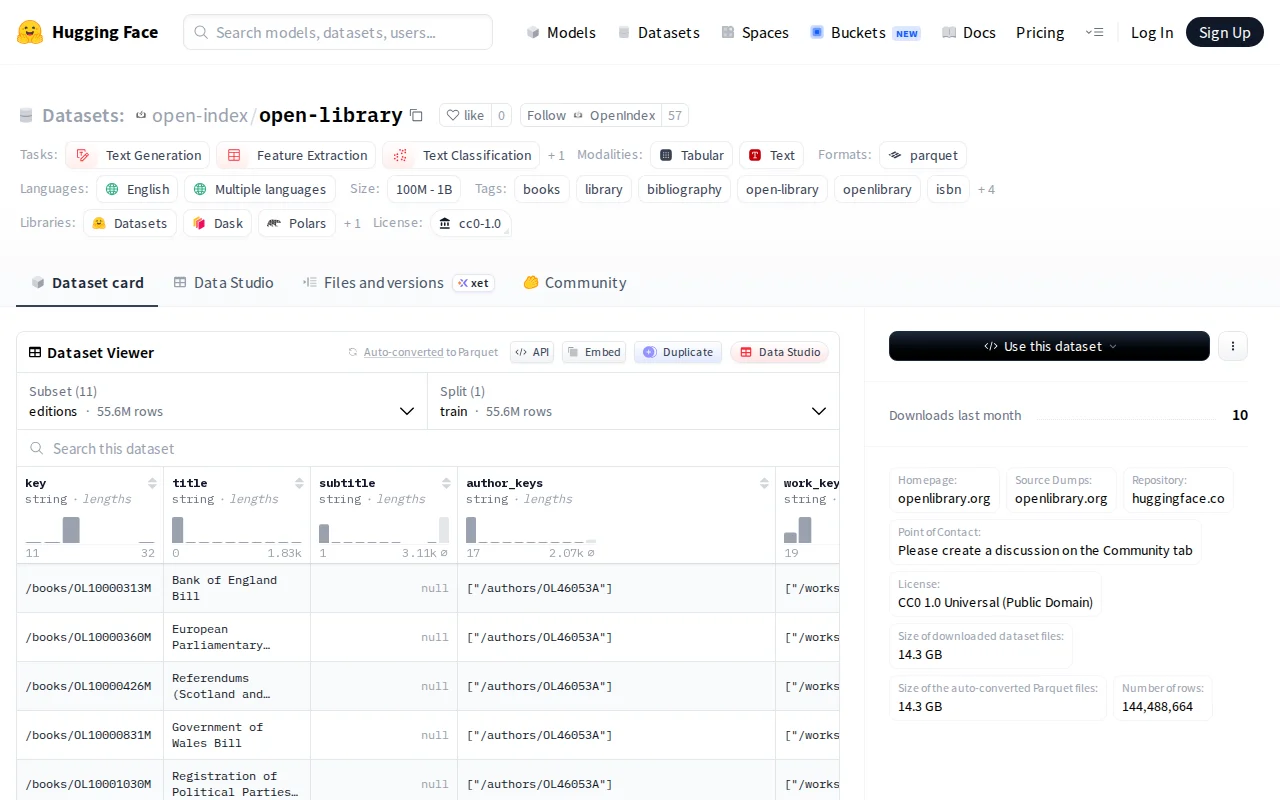
Clean Parquet dump of 55M Open Library rows saves weeks of data cleaning.
ML Engineers, Data Scientists
Google Books API · Internet Archive Dumps · Goodreads Datasets
518k Vietnamese legal documents fill a massive gap in Southeast Asian NLP datasets.
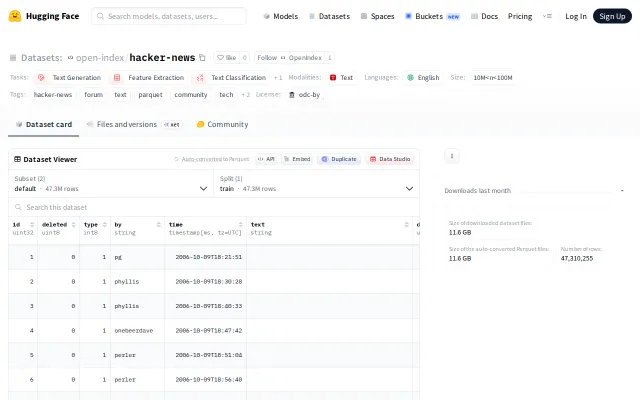
47M HN items in Parquet, auto-updating every 5 minutes on Hugging Face.
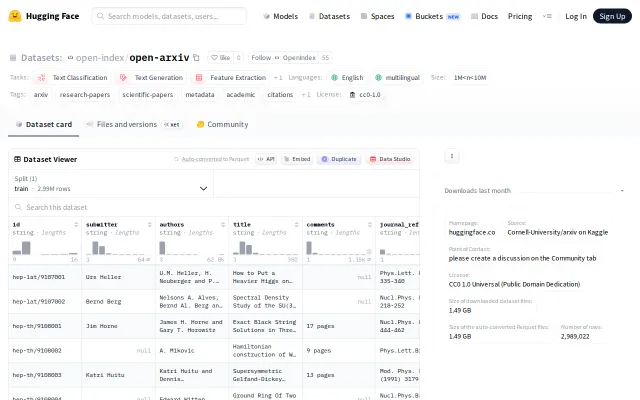
Pre-cleaned ArXiv metadata in Parquet saves hours of ETL pipeline work.
Cross-platform dataset search with health scores when Kaggle and HF are fragmented.
MCP-native tool lets AI agents fetch and clean datasets without human intervention.
MCP server lets agents autonomously build ML datasets from search to export without manual work.