Data●●Solid
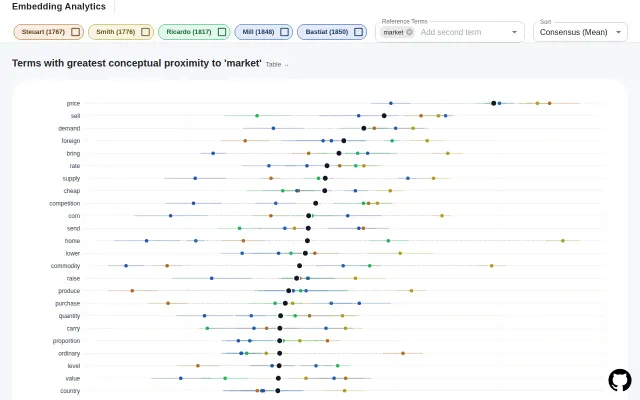
Embedding Similarity with Confidence Intervals
Confidence intervals on embeddings distinguish real semantic drift from model noise.
Big BrainNiche Gem
areebms
103mo ago
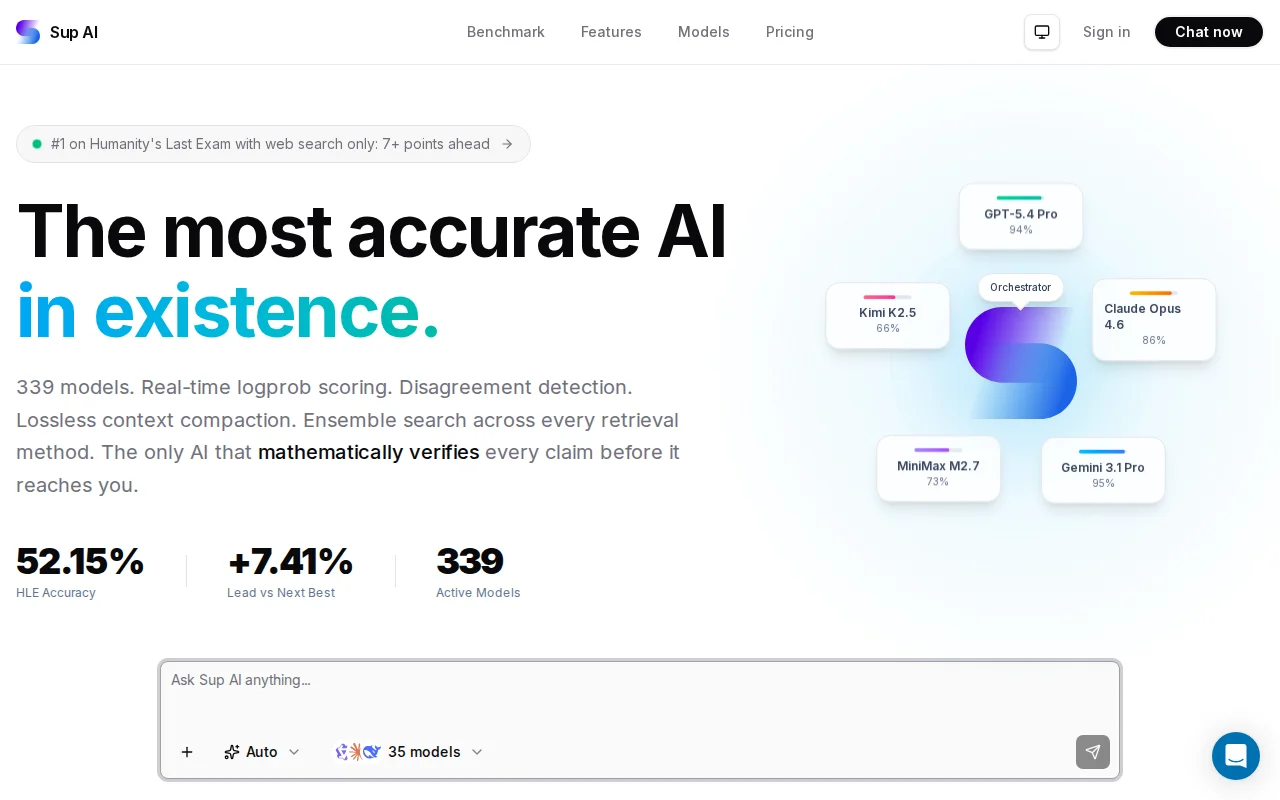
Entropy-weighted ensemble beats best individual model by 7+ points on Humanity's Last Exam.
Researchers and users needing high-accuracy AI responses
Mixture of Experts · AI ensemble platforms
I started working on this because no single AI model is right all the time, but their errors don’t strongly correlate. In other words, models often make unique mistakes relative to other models. So I run multiple models in parallel and synthesize the outputs by weighting segments based on confidence. Low entropy in the output token probability distributions correlates with accuracy. High entropy is often where hallucinations begin.
My dad Scott (AI Research Scientist at TRI, PhD from UCLA) is my research partner on this. He sends me papers at all hours, we argue about whether they actually apply and what modifications make sense, and then I build and test things. The entropy-weighting approach came out of one of those conversations.
In our eval on Humanity's Last Exam, Sup scored 52.15%. The best individual model in the same evaluation run got 44.74%. The relative gap is statistically significant (p < 0.001).
Methodology, eval code, data, and raw results:
- https://sup.ai/research/hle-white-paper-jan-9-2026
- https://github.com/supaihq/hle
Limitations:
- We evaluated 1,369 of the 2,500 HLE questions (details in the above links)
- Not all APIs expose token logprobs; we use several methods to estimate confidence when they don't
We tried offering free access and it got abused so badly it nearly killed us. Right now the sustainable option is a $5 starter credit with card verification (no auto-charge). If you don't want to sign up, drop a prompt in the comments and I'll run it myself and post the result.
Try it at https://sup.ai. My dad Scott (@scottmu) is in the thread too. Would love blunt feedback, especially where this really works for you and where it falls short.
Confidence intervals on embeddings distinguish real semantic drift from model noise.
3,225 trials prove frontier models confidently misattribute teen writing to adults.
Catches when authorized agents are being manipulated, not just blocking unauthorized access.
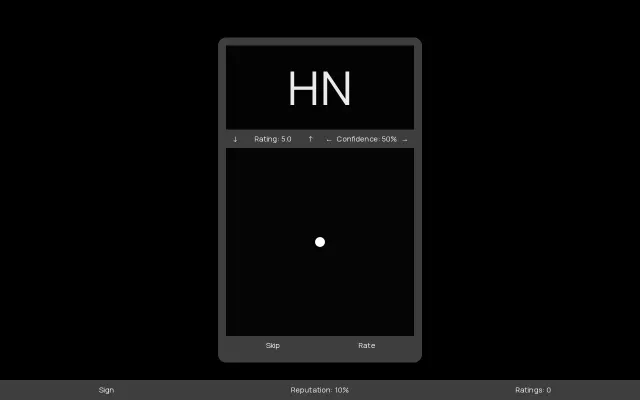
Wilson-bound reputation scoring for raters, but it's a single-page calculator.
EU-hosted exam platform with Safe Exam Browser when US tools violate GDPR.
Four decision outcomes including compute redirect—prompt injection detected before policy runs.