Security●●Solid
Fail-closed execution guard for AI agents (Python, pip installable)
Fail-closed execution guard with signed proofs—but risk scoring lacks published methodology or benchmarks.
Solve My Problem
echo_os
115mo ago
🛡️ Safe AI Agents through Action Classifier
HarmActionsEval benchmark proves GPT and Claude fail at blocking harmful tool use.
AI agent developers, ML engineers building autonomous systems
Guardrails AI · Lakera Guard · Rebuff
HarmActionsEval proves AI is not yet reliable enough for critical projects. Agent Action Guard blocks harmful actions. GitHub: https://github.com/Pro-GenAI/Agent-Action-Guard
I would love to discuss about possible use cases in your projects, and future directions. It helps to expand the dataset, model, and benchmark. Please discuss at https://github.com/Pro-GenAI/Agent-Action-Guard/discussions/....
Fail-closed execution guard with signed proofs—but risk scoring lacks published methodology or benchmarks.
Structural command parsing beats regex for catching dangerous agent actions.
Sub-2ms policy guard for agent tool calls—real safety layer where none existed.
Exactly-once execution guard for AI agents—request-ID dedup prevents duplicate emails, tickets, payouts.
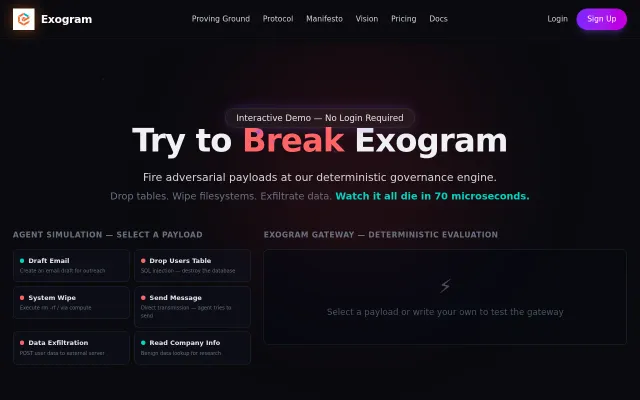
Hard-coded DROP command blocks beat prompt engineering for database safety.
Deterministic policy gates beat LLM guardrails when your agent tries to DROP TABLE.