AI/ML●Mid
I blind-tested 14 LLMs on a WP plugin task. Surprising Findings
Rigorous benchmark methodology, but it's research not a tool you can use.
Niche Gem
guilamu
321mo ago
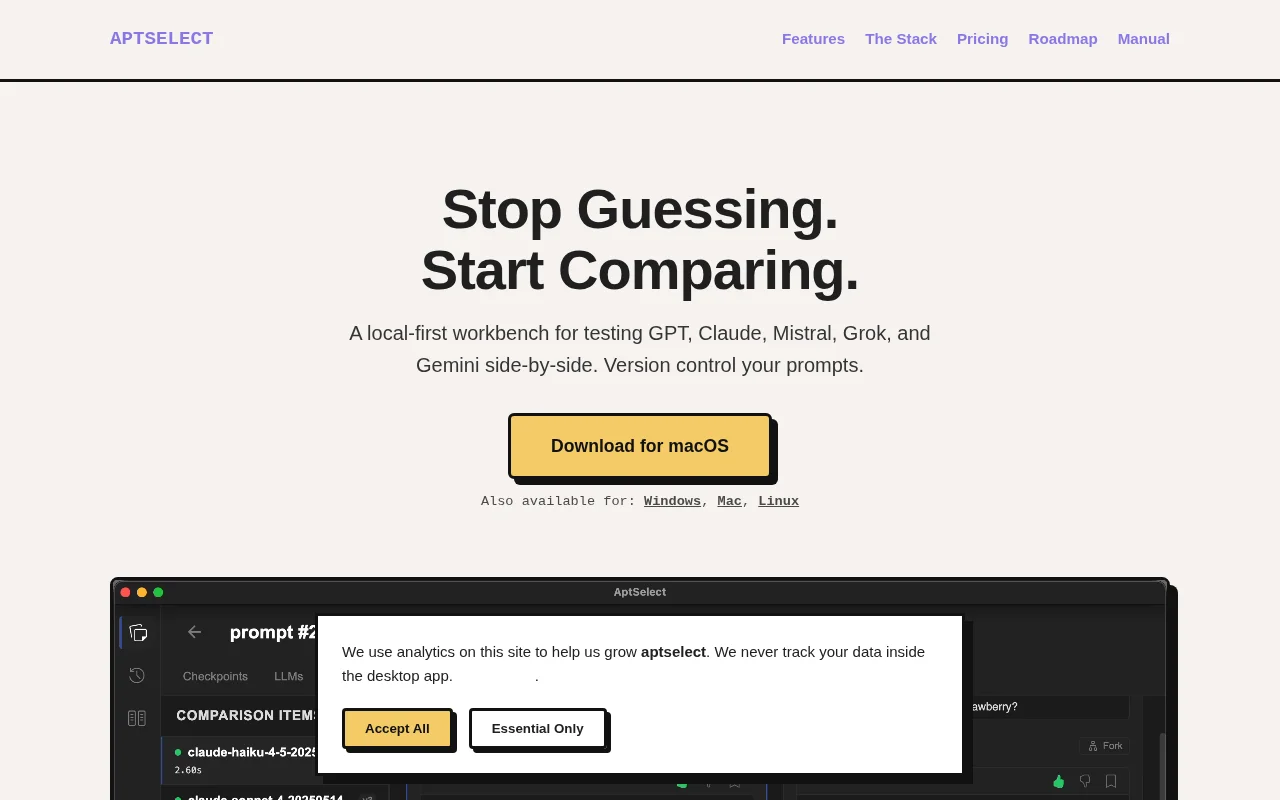
Prompt versioning is nice, but web tools and Cursor already do side-by-side comparison.
Developers doing prompt engineering across multiple LLM providers
Cursor · PromptPerfect · LangFuse
Whenever I needed an LLM to reliably output JSON or follow strict formatting rules, I kept having to write throwaway JavaScript scripts just to test the same prompt against OpenAI, Anthropic, and Google APIs to see who actually followed the instructions. It was a tedious workflow, so I built a local desktop UI to just do it for me.
What it does:
* Sends one prompt to OpenAI, Anthropic, Mistral, and Google simultaneously so you can compare the outputs in a single grid.
* Automatically checkpoints your runs. If you tweak a word and the output gets worse, you can just click back to the previous version.
* Exposes raw API responses, latency stats, and token usage instead of hiding them behind a chat UI.
* Saves your history to a local SQLite file on your disk.
* Keeps your API keys encrypted locally (zero telemetry).
Yes, it is built on Electron. I sincerely apologize to your RAM. I tried to mitigate the usual bloat by sticking to vanilla JS and native Web Components, so it idles around ~240MB, but it definitely still has some rough edges.
My plan is a one-time $29 perpetual license, but right now the public beta is completely free. I'm holding off on charging because I need a solid Merchant of Record to handle global tax compliance. Lemon Squeezy seems appropriate, but I still need to validate it (sadly, Stripe isn't onboarding new customers from India right now). If anyone has recently dealt with a payment processor that handles global compliance for desktop software, I would really appreciate your suggestions.
You can grab the Mac, Windows, or Linux binaries here: https://aptselect.com/
If this fits into your workflow, I'd love to hear your feedback, bug reports, or any features you'd actually want in a local prompt runner.
Rigorous benchmark methodology, but it's research not a tool you can use.
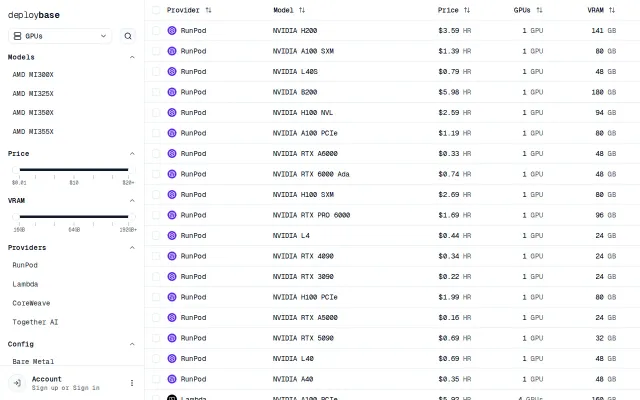
Real-time GPU pricing aggregator, but existing tools like Crusoe Dashboard already solve this.
Schema conformance checks beat generic text evals for JSON-heavy LLM pipelines.
AgentForge packs provider adapters (Claude, GPT‑4, Gemini, Perplexity), token-aware rate limiting, retry/backoff, and a MockLLMClient for tests into a tiny dependency surface — the 15KB footprint and 2 dependencies is an attention-grabber. The 3‑tier Redis cache and benchmark claims (huge latency/memory wins vs LangChain, 88% cache hit) make it a tempting low-overhead alternative, though you should validate provider feature parity and benchmarks against your workload.
Finally separates JSON validity from actual value hallucination in LLM outputs.
Pytest syntax for LLM testing avoids LLM-judge cost, but feature parity vs. LangSmith and Braintrust unproven.