AI/ML●●Solid
I built an open source dication tool based on benchmarks
Benchmarks 34 local speech models so you don't have to guess which one works.
Solve My ProblemDark Horse
emillykkeg
102mo ago
CLI to tell you if an ML model will fit and run on your device, using real benchmarks + lightweight estimation.
Real benchmark database for edge ML when most tools only guess at performance.
Edge ML developers, embedded engineers, ML practitioners deploying to hardware
MLPerf · Papers With Code · HuggingFace Model Hub
So I built willitrun, a small CLI that tries to answer that upfront.
It checks whether a model is likely to fit and run on a given device. When benchmark data exists, it uses that first; otherwise it falls back to a lightweight estimate. Currently covers 482 benchmarks across 88 devices (desktop GPUs, server hardware, Apple Silicon, and NVIDIA Jetson) with HuggingFace model name resolution built in.
Right now the goal is not to be perfect, but to be useful enough to avoid obviously bad choices before spending time downloading or testing models manually. It's also useful for edge devices like a Jetson Orin because you can check performance without physically accessing the hardware.
Most public benchmarks focus on LLMs, but out of personal interest I tried to include other categories as well.
I would be very interested in feedback, especially around cases where the estimates are off or where benchmark coverage is missing.
Benchmarks 34 local speech models so you don't have to guess which one works.
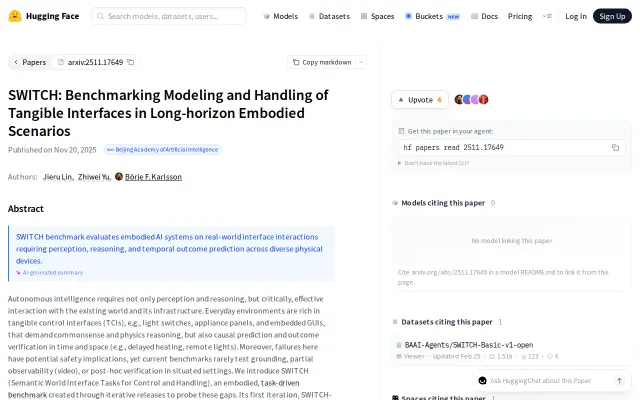
First benchmark testing if AI agents can actually flip light switches and read appliance panels.
11 model families ported to Core AI with verified on-device benchmarks on iPhone 17 Pro.
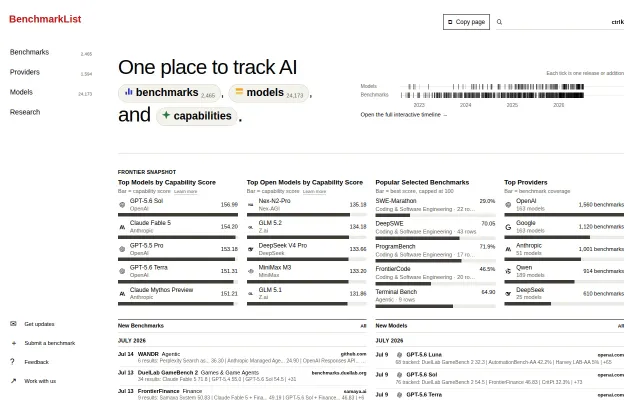
Finally, a single source of truth for the fragmented AI eval landscape.
Just another wallpaper site, but better organized than most free alternatives.
Paired seed comparison beats two-sample tests for detecting benchmark regressions.