AI/ML●●Solid
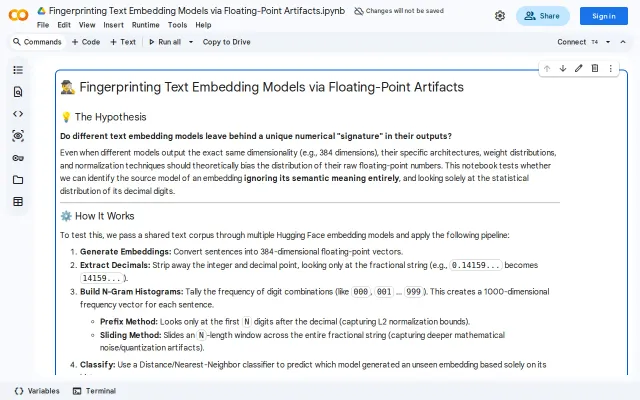
Fingerprinting Text Embedding Models via Floating-Point Artifacts
Identifies embedding models from digit patterns alone, ignoring semantic content entirely.
Big BrainWizardry
yantrams
104mo ago
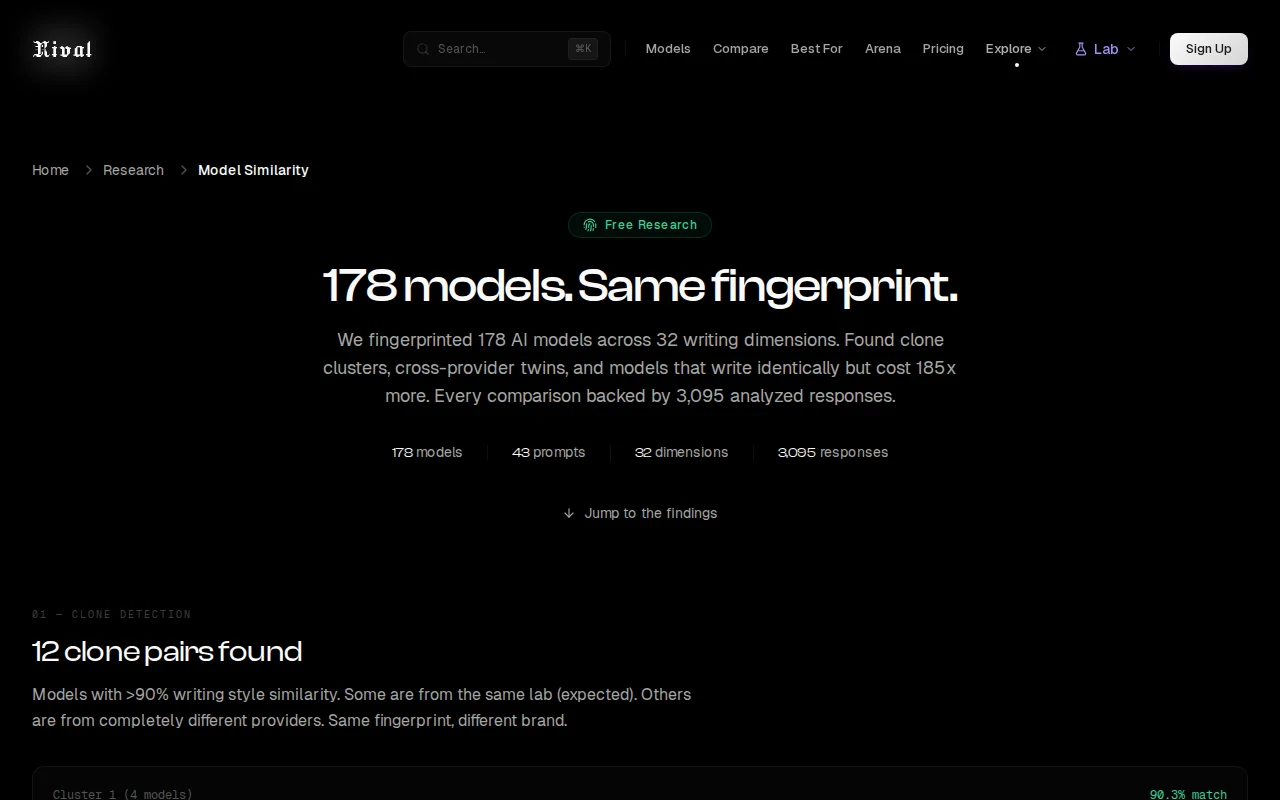
Found Gemini Flash writes 78% like Claude Opus but costs 185x less.
Developers and businesses selecting cost-effective AI models
LMSys Arena · Artificial Analysis · ModelBench
Some findings:
- 9 clone clusters (>90% cosine similarity on z-normalized feature vectors) - Mistral Large 2 and Large 3 2512 score 84.8% on a composite metric combining 5 independent signals - Gemini 2.5 Flash Lite writes 78% like Claude 3 Opus. Costs 185x less - Meta has the strongest provider "house style" (37.5x distinctiveness ratio) - "Satirical fake news" is the prompt that causes the most writing convergence across all models - "Count letters" causes the most divergence
The composite clone score combines: prompt-controlled head-to-head similarity, per-feature Pearson correlation across challenges, response length correlation, cross-prompt consistency, and aggregate cosine similarity.
Tech: stylometric extraction in Node.js, z-score normalization, cosine similarity for aggregate, Pearson correlation for per-feature tracking. Analysis script is ~1400 lines.
Identifies embedding models from digit patterns alone, ignoring semantic content entirely.
Fun stat visualization and shareable cards, but code analysis tools already exist; treats style as personality, not substance.
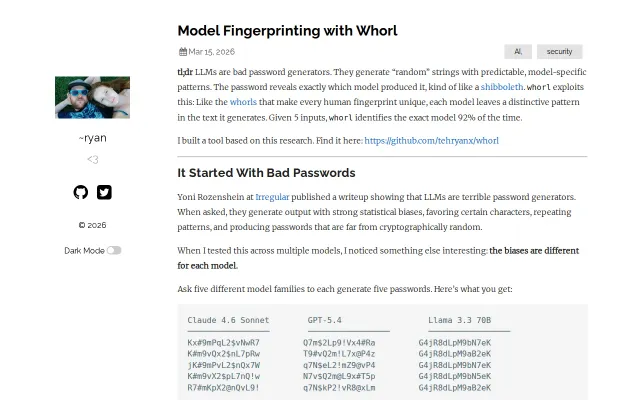
Identifies LLM models by password bias patterns when they refuse to tell you.
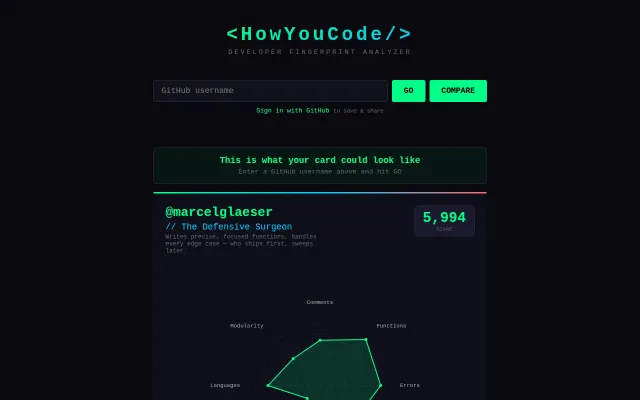
Infers dev archetype from GitHub data, but signal-to-noise on remote collaboration is unproven.
Structural JSONL fingerprinting that ignores key order using simdjson.
Static HTML AI news digest clustered by semantic similarity instead of chronological.