AI/ML●●Solid
I benchmarked how good LLMs are at proofreading English
Agent loop proofreading evals where HELM and LMSys are too generic.
Solve My ProblemShip It
artursapek
321mo ago
One brain. Many bodies. Orchestration framework for embodied AI built on SCP. LangGraph for physical systems. Zero HTTP between bodies.
Subsumption Architecture revival cuts LLM calls with pattern cache misses.
Robotics developers, embodied AI researchers
LangGraph · CrewAI · AutoGen
Agent loop proofreading evals where HELM and LMSys are too generic.
Interesting methodology but this is a blog post, not a product you can use.
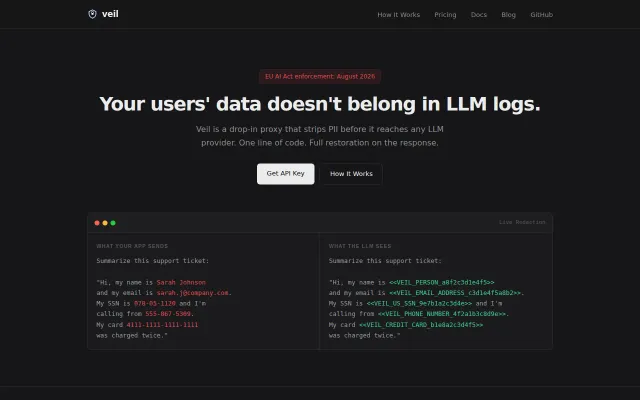
Stops zero-width Unicode bypasses that break standard PII filters before LLM calls.
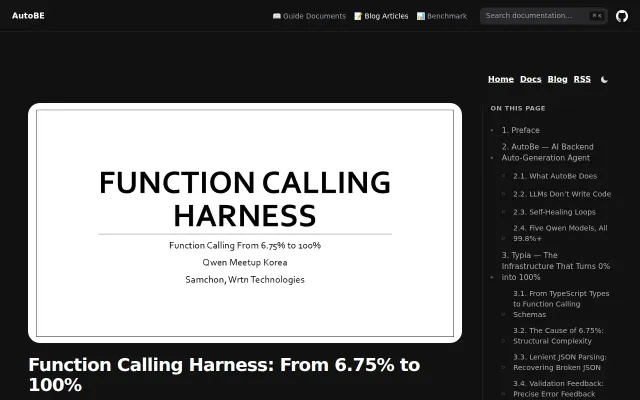
Compiler-level validation turns Qwen's 6.75% structured output success rate into 100%.
LLMs operate pre-built UI components instead of burning tokens regenerating Chart.js every time.
MCP proxy prevents context-window bloat better than naive LLM forecasting.