Developer Tools●●Solid

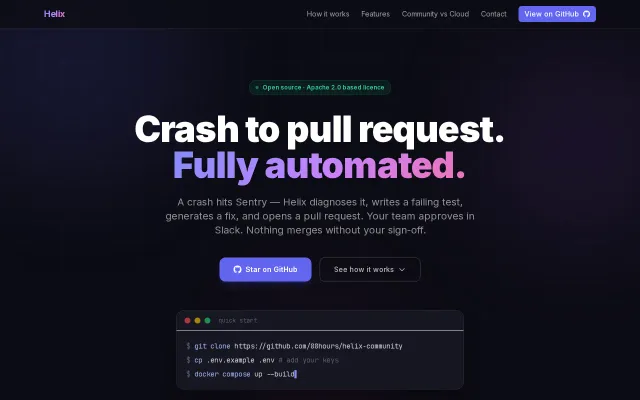
Helix – open-source self-healing back end for production crashes
Four-agent pipeline from Sentry crash to PR, but human approval still required.
Bold BetShip It
NomiJ
111mo ago
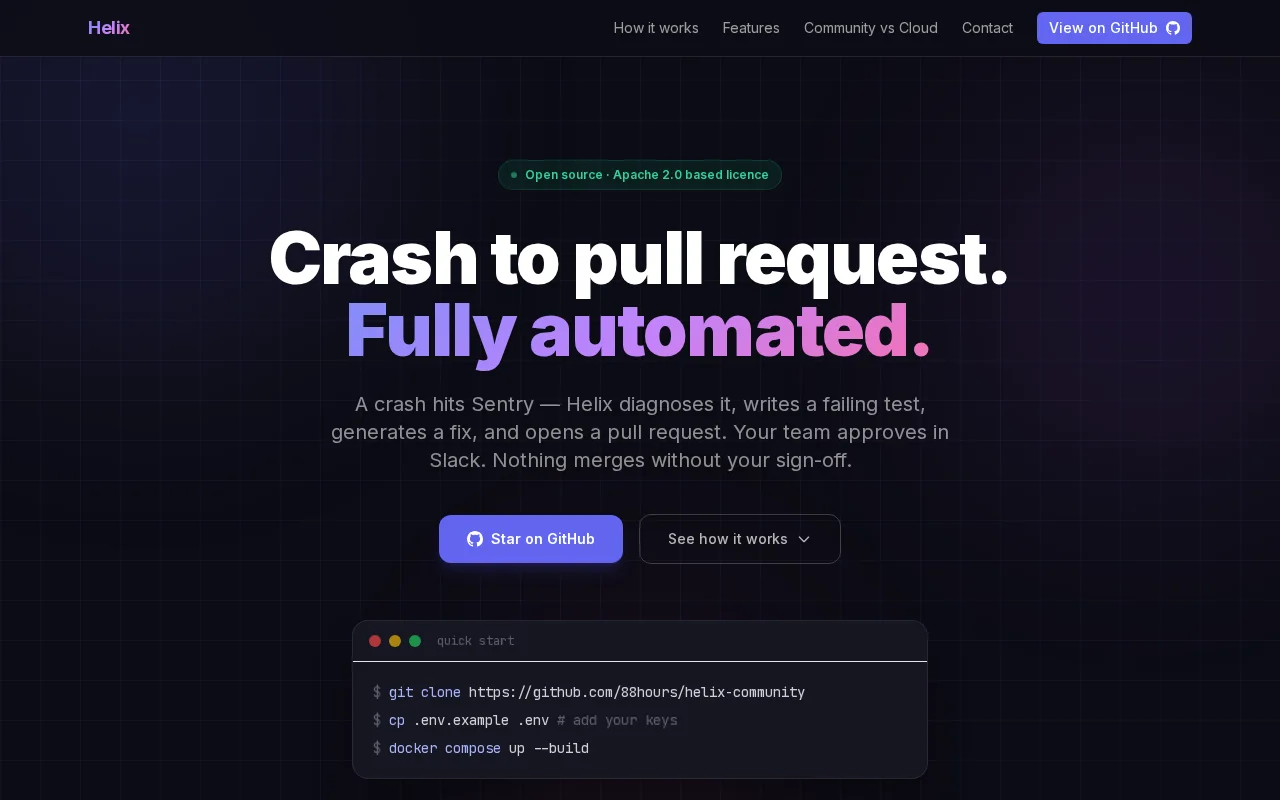
Sentry-to-PR pipeline writes failing tests first, then fixes the bug.
Backend developers and SREs on on-call rotation
Sweep · Codium · GitHub Copilot
So I built Helix. Bug hits Sentry. A multi-agent pipeline kicks off. QA agent writes the failing test first (TDD). Dev agent writes the minimum fix, runs the full suite, opens a PR. You get a Slack message with one button to approve.
Crash to merged PR in under 10 minutes.
Four-agent pipeline from Sentry crash to PR, but human approval still required.
TDD-first auto-fix approach writes failing tests before generating patches, not just patching blindly.
AI daemon hot-patches crashes in 2 seconds—nobody's done self-healing OS like this.
Concrete, hands-on demos — row-level multi-tenancy implemented with Prisma, async jobs via BullMQ/Redis, and tracing through OpenTelemetry/Jaeger — make this a useful reference for people building SaaS backends. It’s not reinventing the stack, but the repo bundles several production patterns and infra pieces together in a way that’s easy to explore; would be stronger with architecture diagrams, runnable quickstart scripts and example data.
Agent writes missing upload_file() mid-task and commits it — no framework can do this.
Zapier alternative that claims to fix itself, but the AI claims need real proof.