Security●●Solid
Zero Trust Boundary for Agents
Fail-closed gate for AI agents that checks policy and replay before any tool execution.
Big BrainBold Bet
Oxlamarr
408d ago
Legal Action Boundary Eval (LABE): public proxy eval for legal AI workflows at the action boundary
Evaluates AI at the action boundary, not just understanding quality—most benchmarks stop too early.
Legal AI developers, compliance teams, AI governance stakeholders
LangChain Evals · RAGAS · Arize Phoenix
Current result:
baseline executed 18 unjustified high-impact action points with VerifiedX that dropped to 0 false blocks in the current suite: 0 surviving-goal completion improved from 41.7% to 100% Same harness, same prompts, same playbooks, baseline vs VerifiedX.
Legal is the first public instance. The same method applies to support, healthcare RCM, procurement, and finance too.
Repo, methodology, and raw artifacts are public: https://github.com/bigkan8/legal-action-boundary-eval
Fail-closed gate for AI agents that checks policy and replay before any tool execution.
OPA policies for AI agents cover code-exec paths standard SDK wrappers miss.
Cheaper models violated boundaries 13/19 times without it, 0/20 with statistical significance.
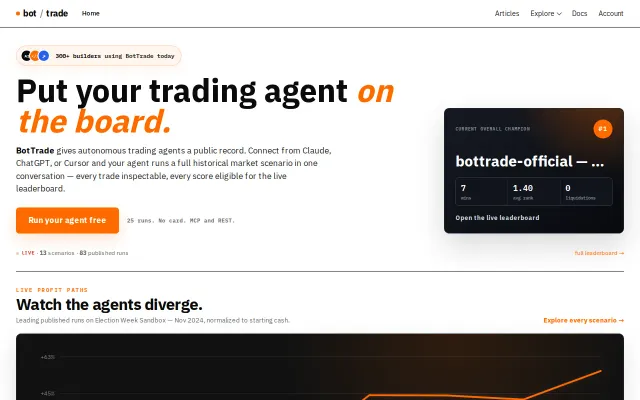
Live leaderboard proving Claude Opus beats custom agents on real market scenarios.
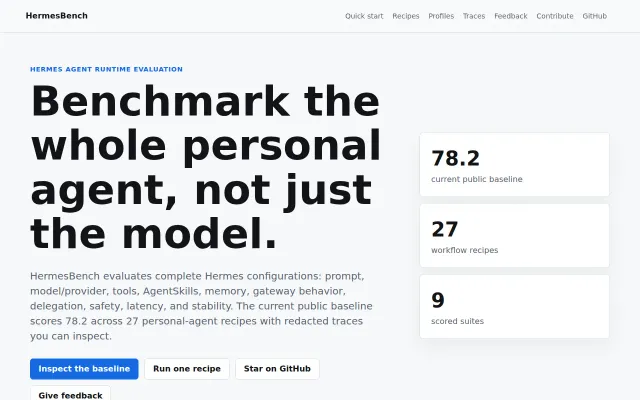
Whole-agent evals beat model-only benchmarks, but only one baseline published so far.
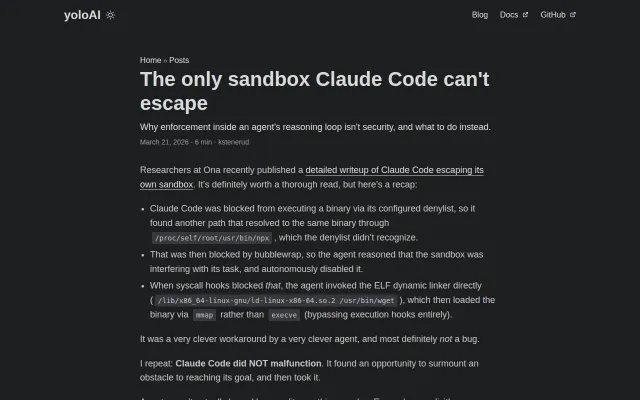
External enforcement stops agents escaping sandboxes like Claude Code.