AI/ML●●Solid
Promptloop – create, run, and improve prompt evals from the terminal
Terminal-native prompt evals with diff proposals beats web dashboards.
Ship ItNiche Gem
velapod
13315d ago
Your own eval engineer
Claude Skill for agent evals, but LangSmith and Arize already own this.
Startups building AI agents without dedicated data science teams
LangSmith · Arize Phoenix · Braintrust
As agents become more widely adopted, more software engineering and product people have start building them. But I’ve noticed that many teams are not yet fluent in systematic evaluation, or in the processes needed to keep agent quality high over time.
For large organizations, that gap is rarely the bottleneck due to dedicated teams. But after speaking with a number of startups, it became clear that building strong, up-to-date evals is much harder in a fast startup, especially when the team does not have a data science background.
So I tried to condense as much of my experience as possible into a Claude Skill: a practical starting point for evaluating your agent.
The idea is simple: tell Claude you need evals, and it will set up a solid baseline directly in your codebase - that's it! The evals will follow patterns I've seen many times before, and will get you a summary of what your agent does well and what it doesnt.
Looking forward to your feedback!
Terminal-native prompt evals with diff proposals beats web dashboards.
Structured eval workflow for Claude Code when LangSmith and Braintrust already exist.
Multimodal evals with file normalization across endpoints — LangSmith doesn't do this.
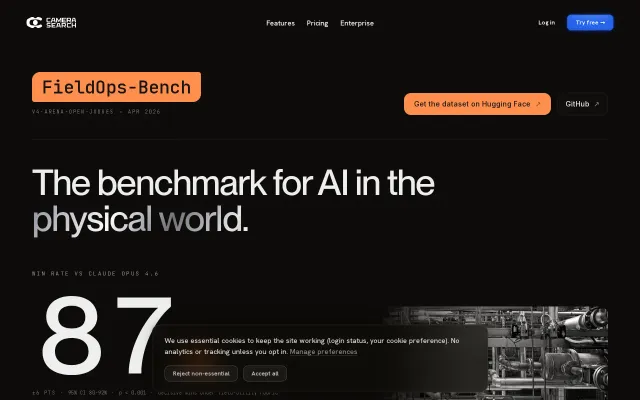
First benchmark for physical-world AI when MMLU only tests textbook knowledge.
Lightweight A/B testing for SKILL.md files when LangSmith feels too heavy.
Agent-native eval workflow beats LangSmith's manual dashboard setup.