Developer Tools●●●Banger
Isartor – Pure-Rust prompt firewall, deflects 60-95% of LLM traffic
Local semantic caching cuts LLM costs without changing your code.
Solve My ProblemSlick
zippode
312mo ago
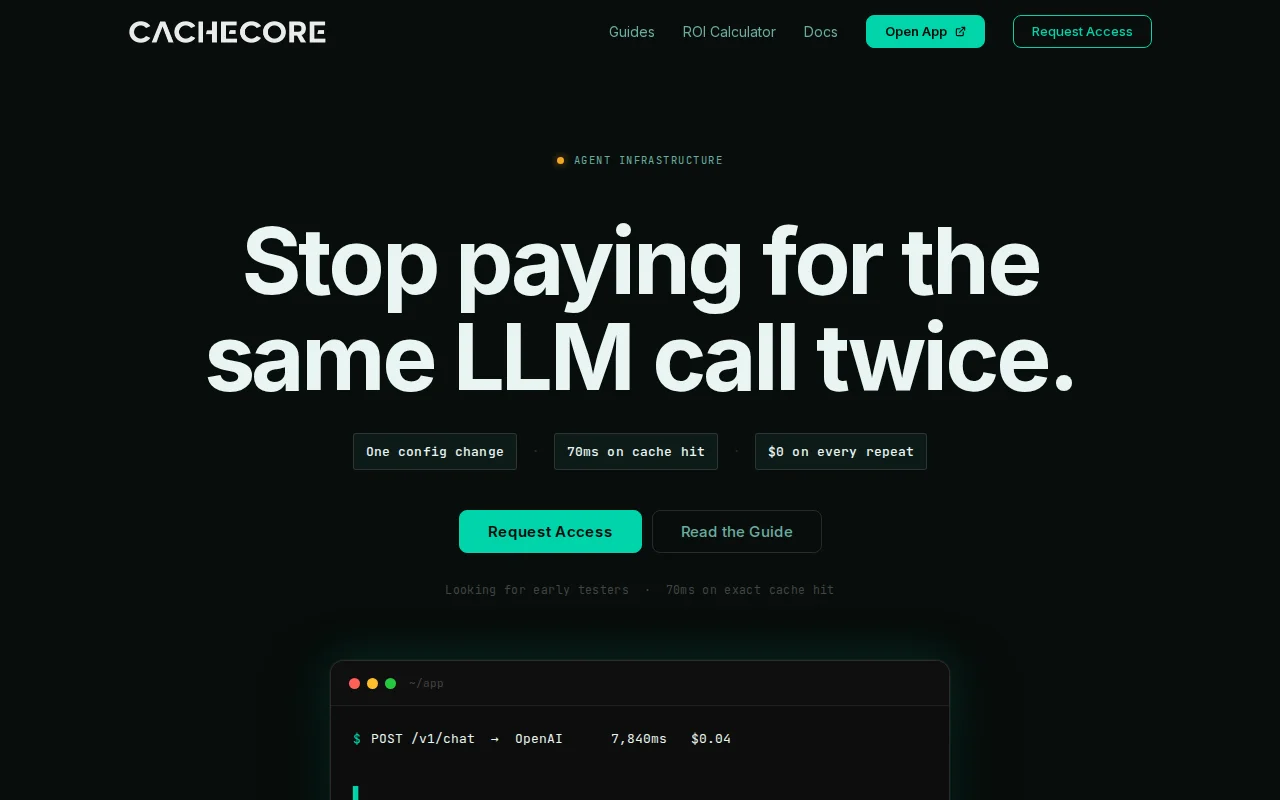
Semantic caching with dependency invalidation beats standard Redis wrappers for agent costs.
Engineers building multi-agent systems or RAG applications
Portkey · LiteLLM · Redis
It works as proxy by replacing the traditional base_url with the CacheCore gateway.
Gateway is built in Rust and there are 2 levels of caching (L1 and L2). There is a automatic mechanism for dependency invalidation.
Compared to other tools: most solutions require you to change the code logic and don't have dependency invalidation.
I started testing on the Legal and Health domains where context reuse is high and query costs add up fast.
Local semantic caching cuts LLM costs without changing your code.
LLM gateway with Redis + Qdrant caching, but LiteLLM does this.
Multi-model LLM router with semantic cache, but caching+fallback already exist (Anthropic, LangSmith, Unify).
Tool result caching for agents when GPTCache and LangChain already do semantic caching.
No Chromium, no pixels—just semantic trees agents actually need in under 200ms.
Proxy-level LLM caching saves tokens during dev without instrumenting your code.