AI/ML●●Solid
2500 vision benchmarks / evals for Vision Language Models
Daily arXiv scraping with Claude classification beats manual curation.
Niche GemBig Brain
zakariaelhjouji
101mo ago
Benchmark any LLM against your data. Pick the best model, then make it better.
Run your own data against GPT-5 and Llama to pick the winner.
ML engineers and prompt engineers
RAGAS · LangSmith · DeepEval
Daily arXiv scraping with Claude classification beats manual curation.
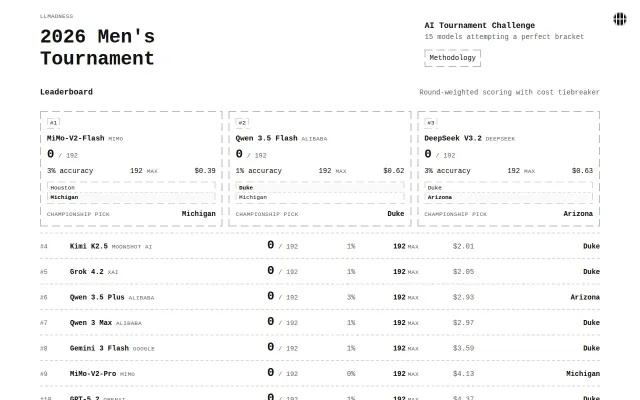
Claude Opus spent $59.55 versus MiMo-Flash at $0.39 for identical bracket predictions.
Shuffling metaphor with real math—97.5% Fisher-Yates quality but solves no obvious problem over standard random.
Transparent benchmark for data analysis LLMs with verifiable notebook artifacts.
Side-by-side model comparison eliminates guessing which speech engine fits your hardware.
Benchmarked dead code finder across FastAPI, Pydantic, Flask—but Vulture, Bandit already solve this.