AI/ML●●Solid
API for 13M+ Indian court cases with citation graphs and vector search
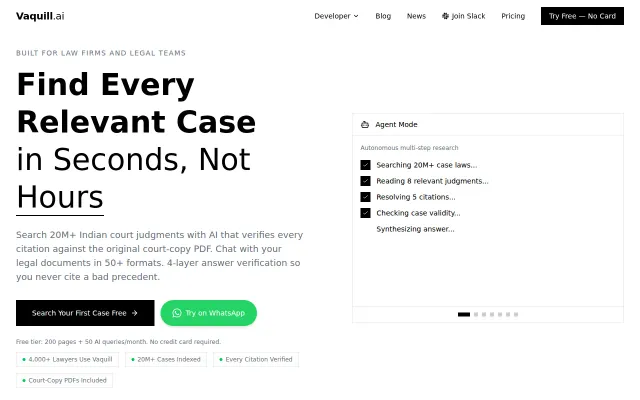
4-layer citation verification catches hallucinated precedents better than Harvey AI.
Niche GemSolve My Problem
pkhodiyar
202mo ago
Versioned snapshots solve the NJDG's lack of historical data and citation stability.
Journalists, legal researchers, and civic tech advocates in India
CourtListener · SCDB
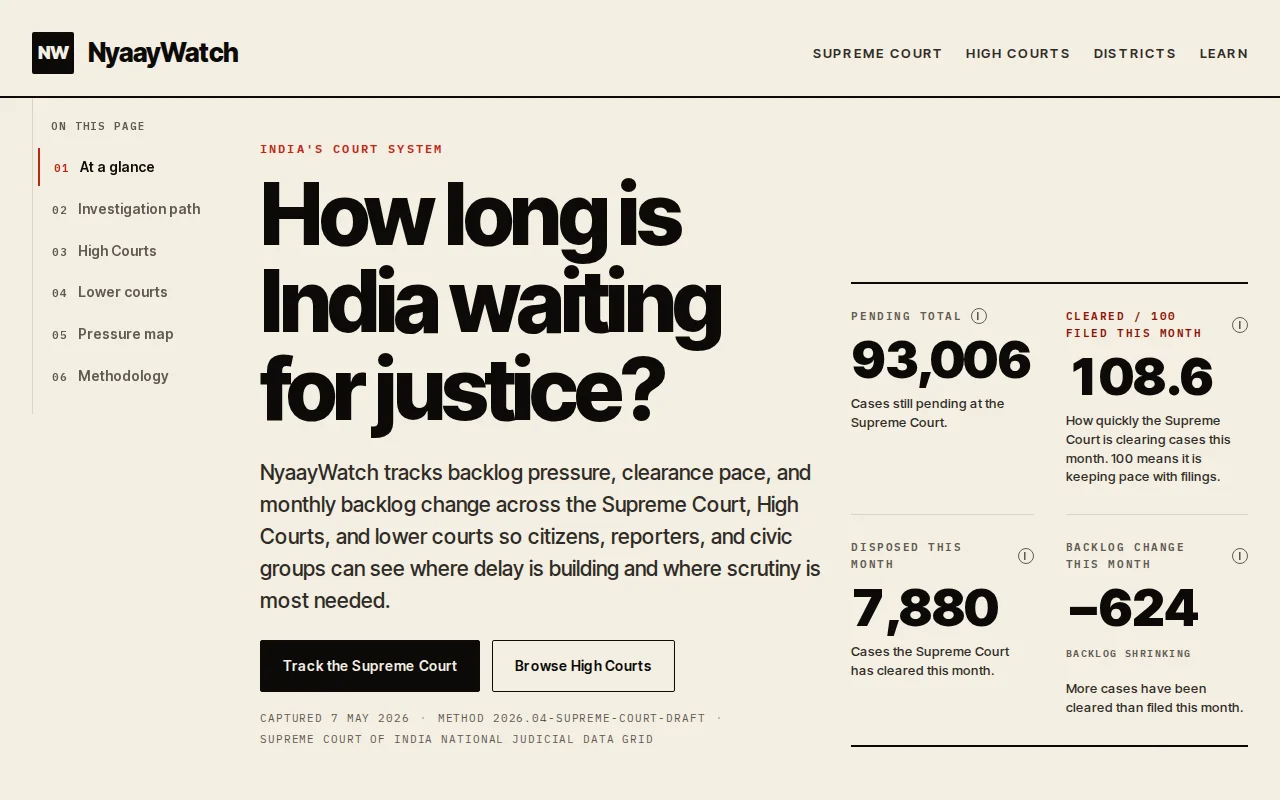
Why it exists: India's National Judicial Data Grid (NJDG) reports pending cases daily, but it doesn't preserve history, has no consistent schema across courts, and gives you no way to cite a specific number on a specific date. The data is public; it just isn't usable. NyaayWatch closes that gap.
Live today: - Supreme Court of India - All 25 High Courts - Lower courts in every state and Union Territory (28 + 8) - Read-only public API with paired /data, /methodology, /api pages - Full methodology behind every figure, with publication ids you can roll back to
Some things HN may find interesting:
- Snapshot-based, not live. The pipeline is fetch → extract → normalize → publish. The publish step is gated on quality + delta checks
- Metrics that depend on missing NJDG inputs are tagged {"state": "missing", "reason": "source-not-published" | ...} rather than silently zeroing. There's a separate cron that emails the official NJDG CPC contact for state rows where pending is non-zero, but filed and cleared are both zero last month (haven't received a reply yet:/)
- Source: https://github.com/rudrakshbhandari/nyaaywatch
Some places to start: - https://nyaaywatch.in/supreme-court - https://nyaaywatch.in/high-courts/bombay - https://nyaaywatch.in/states/uttar-pradesh - https://nyaaywatch.in/learn - curl https://nyaaywatch.in/v1/stats/himachal | jq
Where it's going: NJDG publishes daily but discards history, so the first six months of NyaayWatch is the first six months of dated, queryable judicial data anyone can cite.
Beyond that — undertrial populations (around three-quarters of India's prison population is awaiting trial), translations into Hindi, Tamil, Bengali, Marathi, and the same observability layer for the executive and legislative branches over time.
This is a public alpha. I'd love feedback from anyone who's worked with NJDG, judicial data, civic-tech infrastructure, or anyone passionate about social justice. Contributions are welcome:)
4-layer citation verification catches hallucinated precedents better than Harvey AI.
500 years of Korean court omens mapped to DevOps telemetry with real historical data.
250K users on OSS plugin, now measuring AI coding ROI for teams.
Local-first agent observability without cloud signup — LangSmith alternative that keeps data on your machine.
One-line AI tracing, but LangSmith, LangFuse, Anthropic Workbench already solve observability.
Hallucination guardrails middleware, but is it better than prompt engineering plus Claude?