AI/ML●Mid
Proposal for a real long-term AI memory benchmark
Audited LoCoMo and found 6.4% of answer keys are wrong—benchmarks are broken.
Bold Bet
dial481
402mo ago
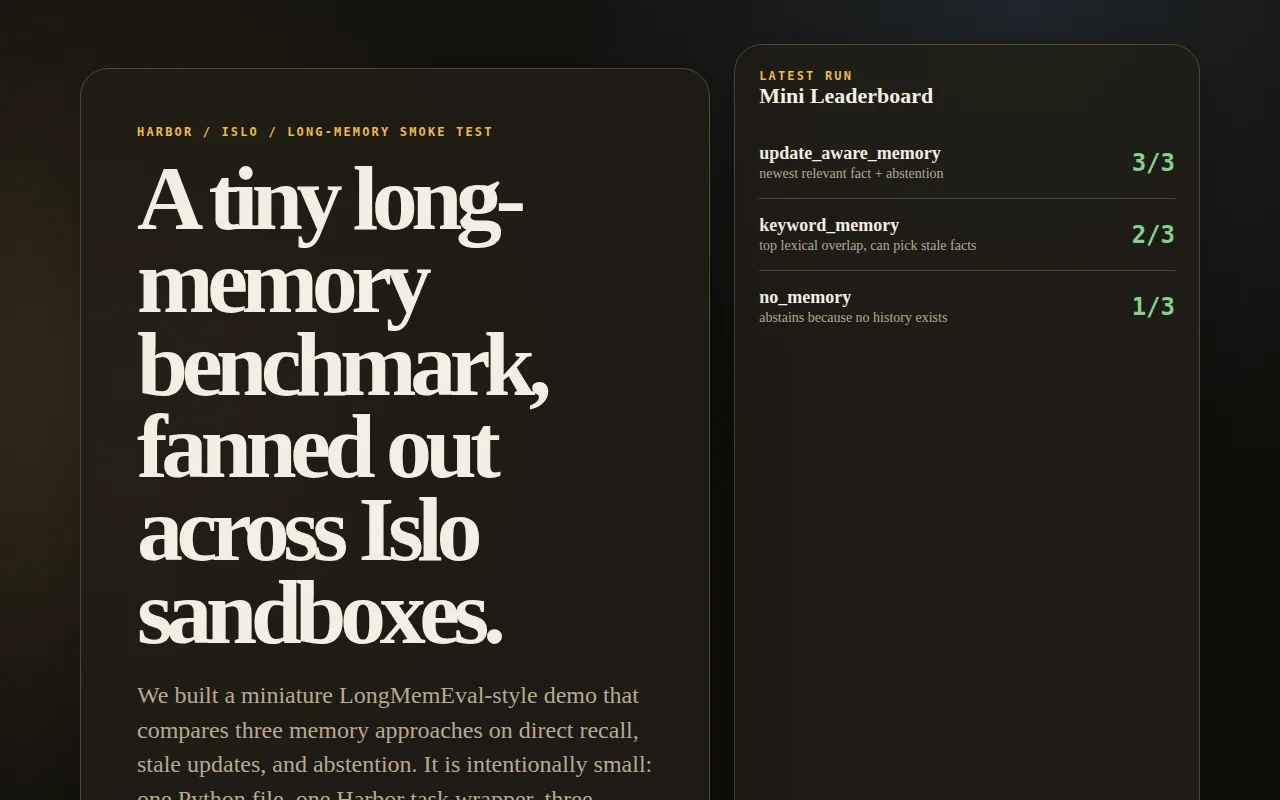
Compresses long-memory evaluation into three questions testing recall, updates, and abstention.
AI researchers evaluating long-term memory systems
LongMemEval · AgentBench · BIG-bench
Audited LoCoMo and found 6.4% of answer keys are wrong—benchmarks are broken.
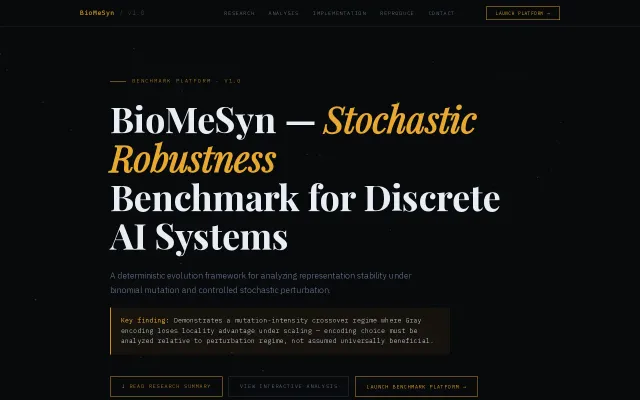
Rigorous perturbation analysis finds encoding behavior is regime-dependent, not universally optimal.
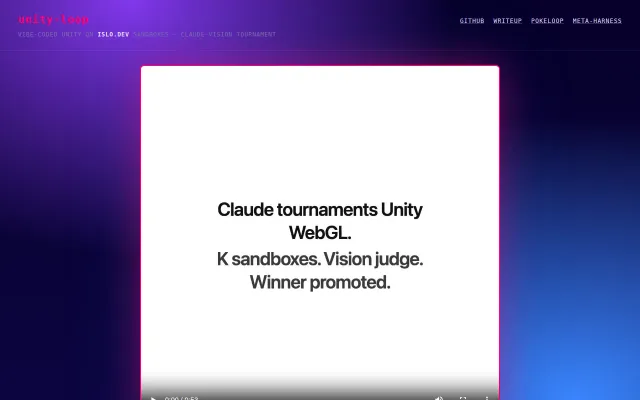
Clever use of parallel islo.dev sandboxes to let Claude vision models judge UI iterations.
Thirty-line agent loop with Docker sandboxing contains blast radius safely.
Demand-paging memory for agents beats context window limits that break Cursor and Devin.
Active memory extraction with GRPO beats passive transcription on LOCOMO benchmarks.