Data●●●Banger
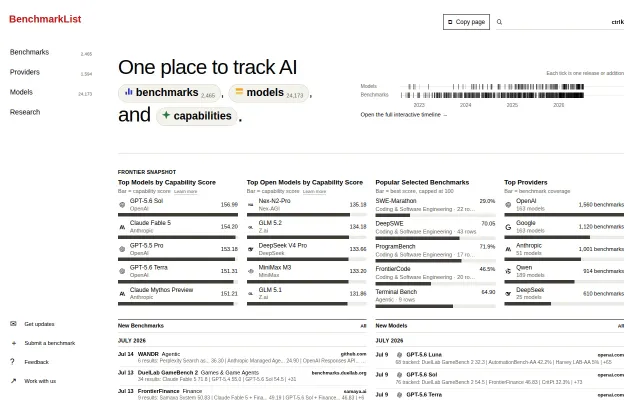
Benchmarklist: track AI benchmarks (2.4k+), models, and capabilities
Finally, a single source of truth for the fragmented AI eval landscape.
Rabbit HoleSolve My Problem
davidtsong
205d ago
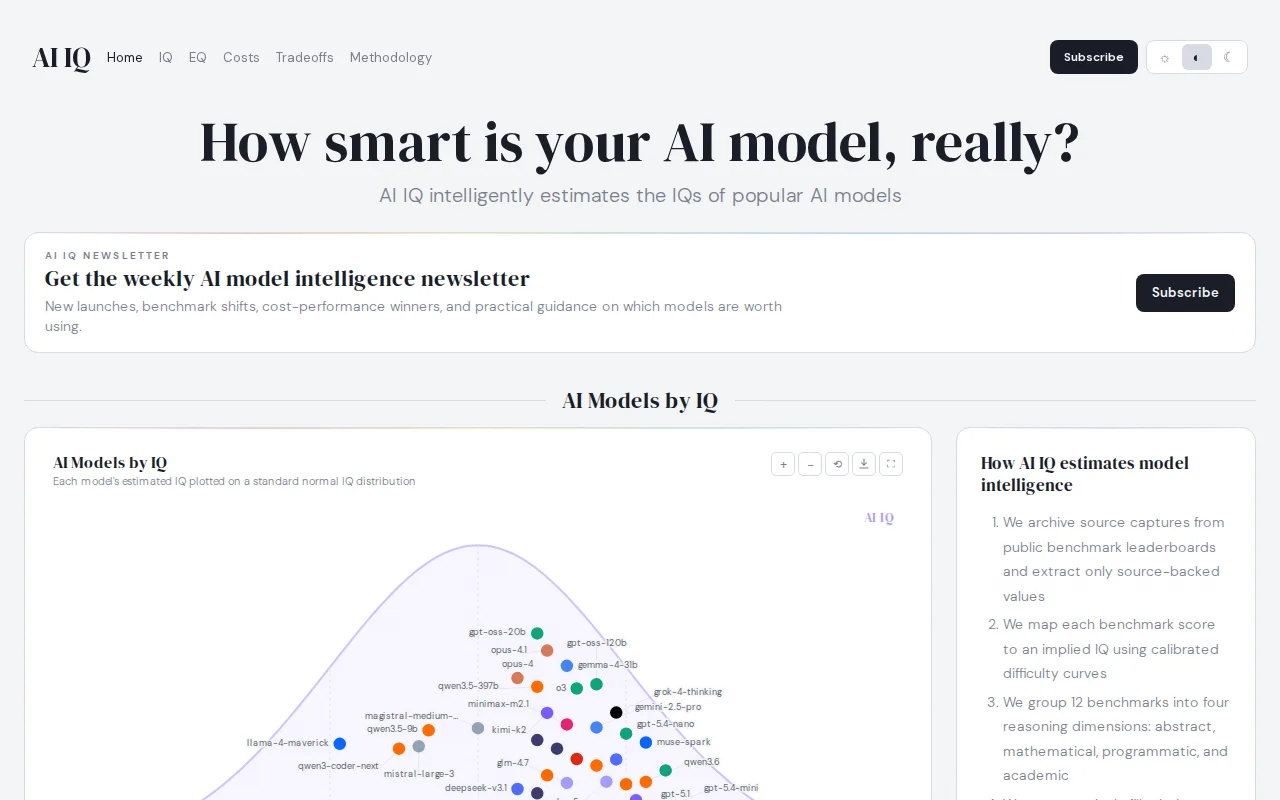
Normalizes disparate benchmarks into a single IQ score, but relies on opaque calibration curves.
AI researchers, developers, and tech enthusiasts tracking model performance.
LMSys Chatbot Arena · Hugging Face Open LLM Leaderboard · Papers With Code
Finally, a single source of truth for the fragmented AI eval landscape.
Fuchsia-inspired capability model for agent benchmarks solves reproducibility existing tools ignore.
Another career dashboard when LinkedIn Salary and Levels.fyi already exist.
Yet another Sharesight alternative in a crowded portfolio tracker space.
Teaches you to spot when benchmark scores are noise versus signal before you trust a paper.
SJF4J beats Jayway by 7x on native objects, but JSONPath is a crowded category.