AI/ML●Mid
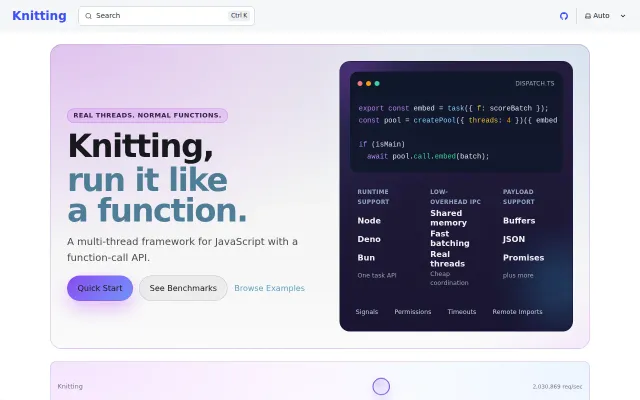
Modular – drop AI features into your app with two function calls
Yet another AI plumbing layer — LangChain and Vercel AI SDK already exist.
Ship It
modular_dev
713mo ago
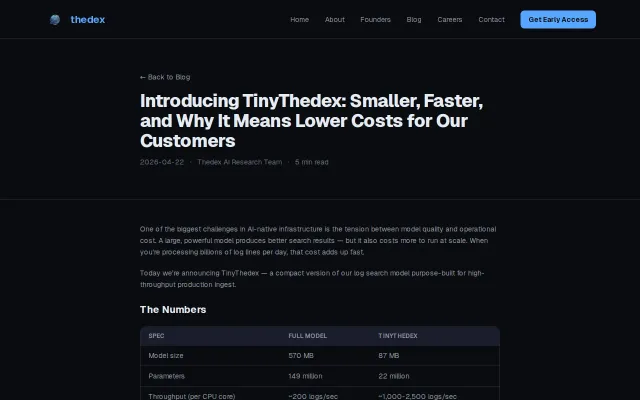
Foundation model for tiny devices; 14mb, 26m params, 1-6k toks/sec on mobiles, wearables smart home and robots.
Distilled Gemini tool-calling into a 26M model that runs at 1200 tok/s on phones.
Edge AI developers and mobile app engineers building on-device agents
FunctionGemma · Qwen · Granite
We were always frustrated by the little effort made towards building agentic models that run on budget phones, so we conducted investigations that led to an observation: agentic experiences are built upon tool calling, and massive models are overkill for it. Tool calling is fundamentally retrieval-and-assembly (match query to tool name, extract argument values, emit JSON), not reasoning. Cross-attention is the right primitive for this, and FFN parameters are wasted at this scale.
Simple Attention Networks: the entire model is just attention and gating, no MLPs anywhere. Needle is an experimental run for single-shot function calling for consumer devices (phones, watches, glasses...).
Training: - Pretrained on 200B tokens across 16 TPU v6e (27 hours) - Post-trained on 2B tokens of synthesized function-calling data (45 minutes) - Dataset synthesized via Gemini with 15 tool categories (timers, messaging, navigation, smart home, etc.)
You can test it right now and finetune on your Mac/PC: https://github.com/cactus-compute/needle
The full writeup on the architecture is here: https://github.com/cactus-compute/needle/blob/main/docs/simp...
We found that the "no FFN" finding generalizes beyond function calling to any task where the model has access to external structured knowledge (RAG, tool use, retrieval-augmented generation). The model doesn't need to memorize facts in FFN weights if the facts are provided in the input. Experimental results to published.
While it beats FunctionGemma-270M, Qwen-0.6B, Granite-350M, LFM2.5-350M on single-shot function calling, those models have more scope/capacity and excel in conversational settings. We encourage you to test on your own tools via the playground and finetune accordingly.
This is part of our broader work on Cactus (https://github.com/cactus-compute/cactus), an inference engine built from scratch for mobile, wearables and custom hardware. We wrote about Cactus here previously: https://news.ycombinator.com/item?id=44524544
Everything is MIT licensed. Weights: https://huggingface.co/Cactus-Compute/needle GitHub: https://github.com/cactus-compute/needle
Yet another AI plumbing layer — LangChain and Vercel AI SDK already exist.
SQLite memory beats JSON bloat; async streaming works—but it's still a Gemini wrapper.
96.4% quality at 1/7th the size—DistilBERT energy for log embeddings.
Swaps postMessage for shared memory, making cross-thread calls 3.5x faster in Deno.
Turns existing OTel traces into a self-improving router against GPT-4.
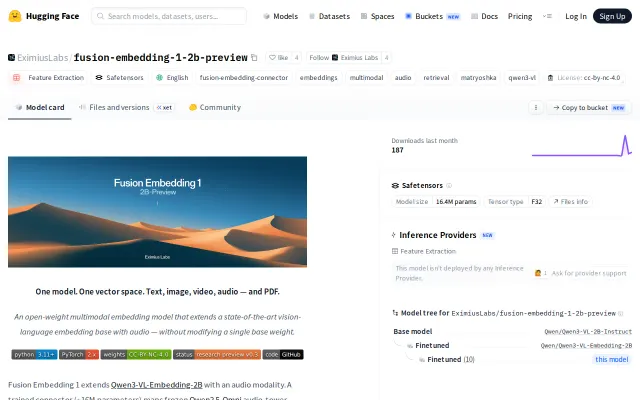
16M trained params beats Gemini Embedding 2 on audio-text retrieval.