Developer Tools●●Solid
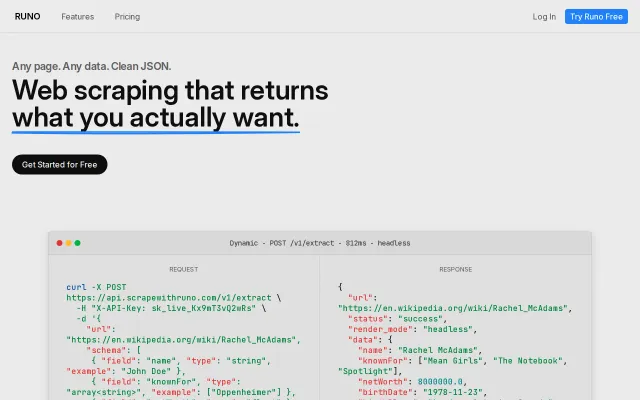
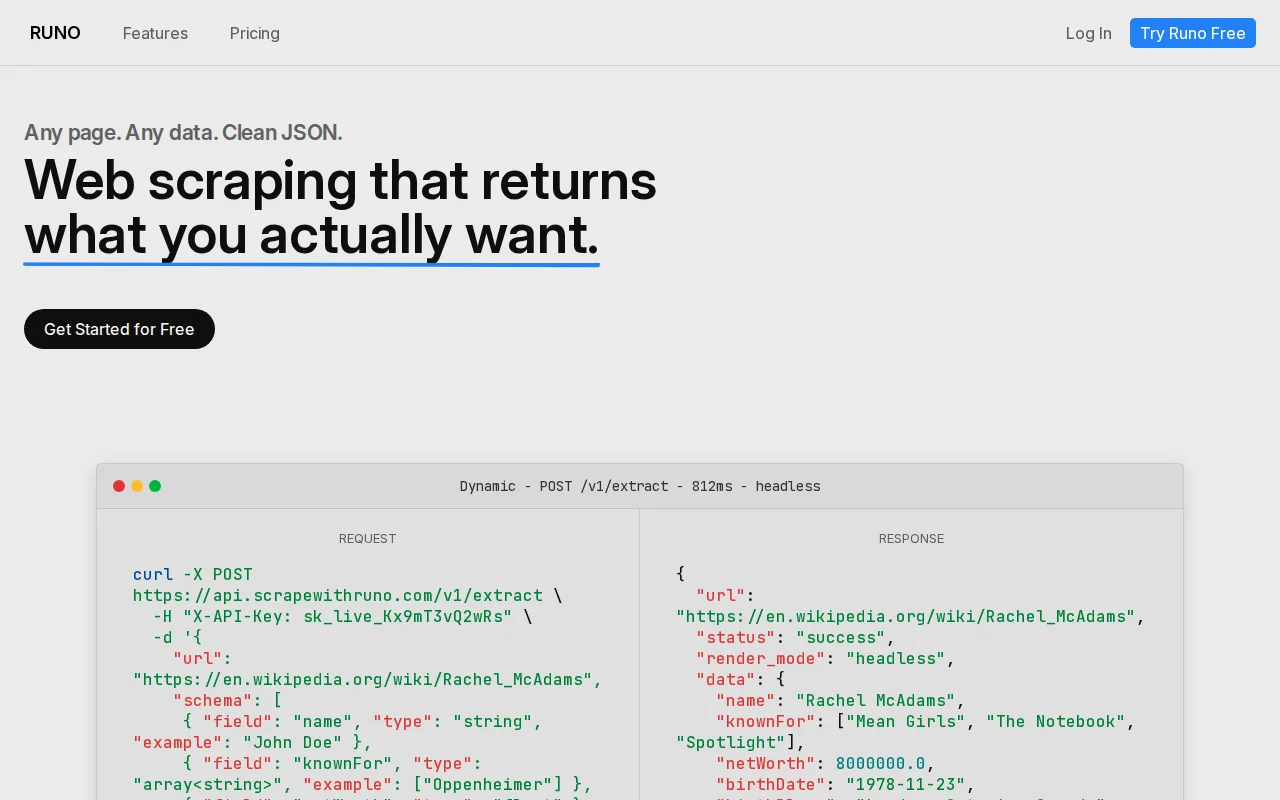
Runo – Scraping API that returns typed JSON, not raw HTML
Schema-driven extraction beats maintaining brittle CSS selectors.
Solve My ProblemSlick
barebearcountry
4026d ago
Yet another scraping API, but the schema-by-example approach is cleaner than competitors.
Backend developers, data engineers building scrapers
Firecrawl · ScraperAPI · JinaAI Reader API
Over the past few weeks, I have been building this non stop. Currently, every scraper API out there solves the site fetching problem but left the extraction of the actual data entirely to users. Runo makes that completely disappear.
For Runo, I went ahead and added JS rendering, stealth mode, and full LLM extraction to make this a fully functional and capable of scraping most if not all sites.
Also, another major problem with current web scrapers is that they charge per feature or bundle them into expensive credit tiers. A single large or JS rendered request can cost 5-75 credits, which means you essentially get nothing out of their plans. Runo is flat per request, no matter the site. At the Scale tier, Runo works out to $0.90 per 1,000 effective requests vs. around $6 for the nearest Firecrawl equivalent. My jaw dropped when I was testing Runo and came across these numbers.
I created a free tier that is 500 requests/month, no credit card required. Take it for a spin and let me what can be improved. I would love feedback.
Schema-driven extraction beats maintaining brittle CSS selectors.
Yet another HN scraper when the Firebase API is already free and public.
Store page shows unavailable, and Twitter scrapers are a dime a dozen.
Free Maps scraper when Apify and ScraperAPI already dominate this space.
Web scraping API with brand enrichment when JinaAI and Firecrawl already dominate.
Yet another JSON validator, but uses TypeScript types instead of JSON Schema.