Developer Tools●●Solid
CPU-only fast OCR for screenshots, images, PDFs, webpages
CPU-only VLM OCR beats Tesseract accuracy without sending data to the cloud.
Solve My ProblemCozy
mrkn1
981mo ago
Snap any image, screenshot, or webpage into plaintext. No GPU. No cloud. One command.
CPU-only VLM OCR beats Tesseract on layout without needing CUDA or cloud APIs.
Developers needing offline OCR, privacy-focused users, automation scripters
EasyOCR · Tesseract · Umi-OCR
CPU-only VLM OCR beats Tesseract accuracy without sending data to the cloud.
CPU-only OCR with clipboard in/out beats Tesseract for modern screenshots.
CPU-only OCR with clipboard round-trip when cloud APIs dominate the space.
Privacy-first screen capture for agents when Rewind and ScreenPipe already exist.
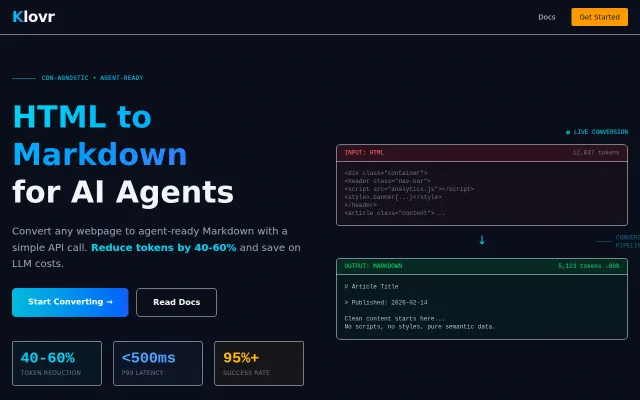
Nice, focused product: site-specific extraction rules (CSS selectors/metadata overrides), edge-first delivery (<500ms p99) and SDKs for Node/Python make it quick to drop into an LLM pipeline and claim 40–60% token savings. That said, HTML→Markdown is a crowded niche (Pandoc, Jina, Firecrawl and dozens of scrapers already exist), so Klovr needs clearer differentiation — e.g. demonstrable extraction accuracy, enterprise-grade rule sharing, or unique model-aware trimming — to move beyond 'handy utility'.
Native macOS image viewer with on-device AI enhancement beats Preview for power users.