AI/ML●●Solid
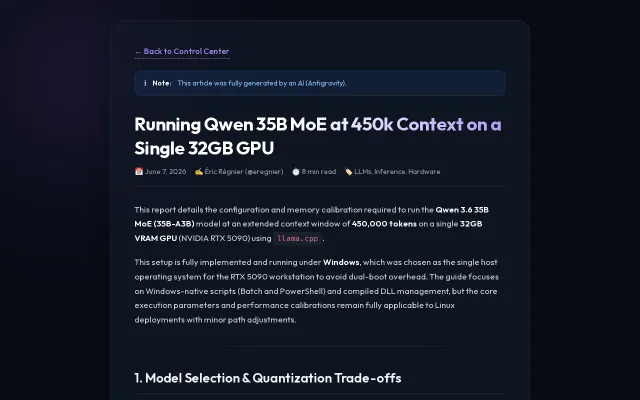
Best setup local LLM found for a 5090 (llama.cpp fork + turboquant)
450k context on 32GB VRAM using turboquant KV cache compression.
Big BrainNiche Gem
utopman
221mo ago
🌸 Run BIOxAI models at home, BitTorrent-style. Fine-tuning and inference up to 10x faster than offloading
BitTorrent-style distributed inference for biology LLMs across consumer GPUs.
Bioinformatics researchers and computational biologists
Petals · Hugging Face Transformers
Earlier I was submitting a sequence to an AI protein folding server and had to wait almost 2 hours. This gave me the idea of trying to modify petals for biology models. Rewriting petals completely for different architectures (genome language models, protein language models) would be difficult, so I decided to start off by just rewriting for a biology tuned llama.
If u wanna try it out, theres a fully setup Google colab linked in the readme, it might not actually run though since it needs a certain amount of people on the network.
450k context on 32GB VRAM using turboquant KV cache compression.
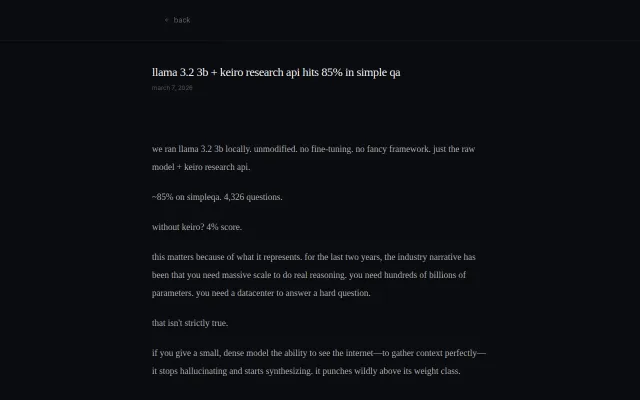
Retrieval-aware inference beats 671B models by showing context matters more than scale.
Found llama.cpp loading models twice in RAM — fixed with host_ptr, 74% reduction.
Fork from failed agent runs and prove fixes before shipping—LangSmith doesn't do this.
Plain JS tone generator with Solfeggio presets when dedicated apps exist.
Reduces SigNoz production infra from 56 CPUs across 10 nodes to managed cloud.