Developer Tools●●●Banger
Cheddar-bench – unsupervised benchmark for coding agents
Unsupervised bug benchmark using agents as both attackers and defenders—novel scoring methodology.
Big BrainWizardryShip It
przadka
904mo ago
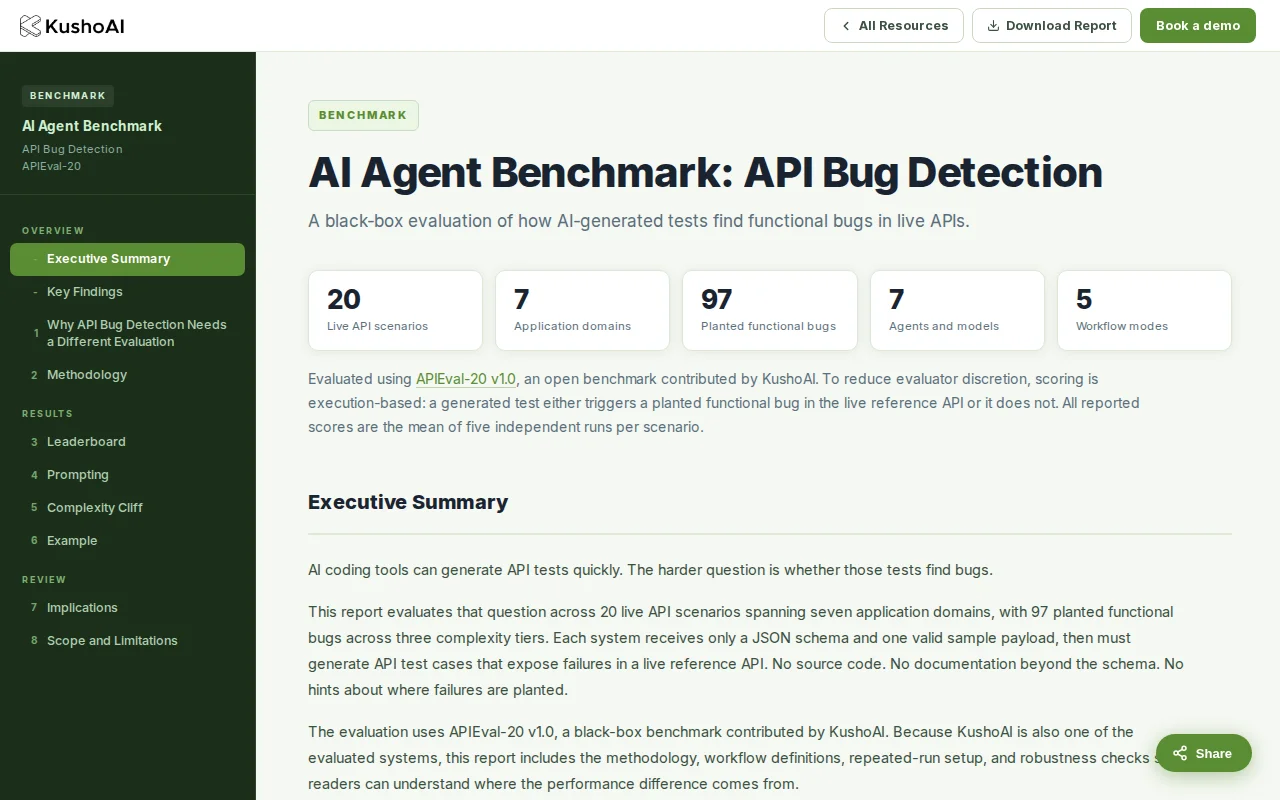
Execution-based scoring with live APIs beats LLM-graded benchmarks, but they evaluated themselves.
Engineering teams evaluating AI testing tools
Cognition Labs · AI2 · LangSmith
Unsupervised bug benchmark using agents as both attackers and defenders—novel scoring methodology.
Tests live in README as plain English; clever partial parsing eliminates Gherkin boilerplate overhead.
Found 250 bugs in 247 engines using a byte-identical consensus oracle nobody else built.
AI finds 250 bugs in LiteLLM, LobeChat, but no demo or accessible entry point.
Landing page is a Cloudflare bot check—no demo, no code, no way to evaluate claims.
AI PR generation for typos and copy, but bug reporting tools already exist elsewhere.