Developer Tools●●●Banger
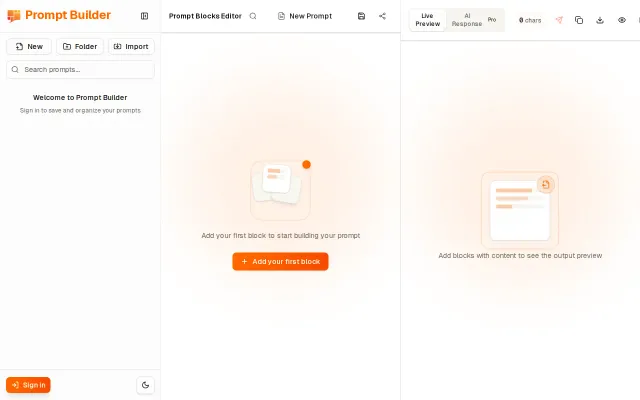
Prompt-run – run .prompt files against any LLM from the terminal
Git-friendly `.prompt` format with `prompt diff` side-by-side output beats scattered Notion docs.
Solve My ProblemShip It
maneeshthakur
103mo ago
Ollama Model Test - Figure out the best model for the task
Prompt-hashed folders make model comparison easy, but Ollama testing tools already exist.
Developers testing local LLM models
lm-evaluation-harness · fmbench · llm-benchmark
I created this script as an easy way to test local Ollama models and keep the test output organized.
When you run the script interactively, it asks which model you want to use, what your prompt is, how many times you want to run it, and (optional) the temperature you'd like to set. It can also be scripted with command-line flags.
The output is saved in Markdown/JSON within an organized file structure for easy comparison. Outputs using the same prompt go into a folder together, each output named for the model tested. Timing data and token counts are also recorded.
The tool is intentionally small and dependency-free (standard library only).
Suggestions welcome.
Git-friendly `.prompt` format with `prompt diff` side-by-side output beats scattered Notion docs.
The block metaphor and live compiled preview are honest, practical improvements for anyone wrestling with long, conditional prompts — toggles for A/B testing and global {{vars}} are especially handy. Multi-model execution and editable response panes show the author thought about iteration and comparison, but the screenshot feels safe and functional rather than boldly new; I want to know how it handles collaboration, exports, and model/credit management.
336× faster tree model inference; compiles sklearn/XGBoost to C99, serves like Ollama.
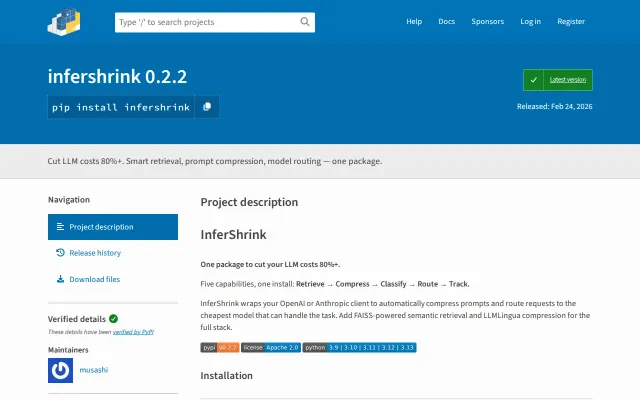
Three-line wrapper cuts LLM costs 80%+ via prompt classification and same-provider routing.
Validates live Firestore docs against schema when other tools only generate types.
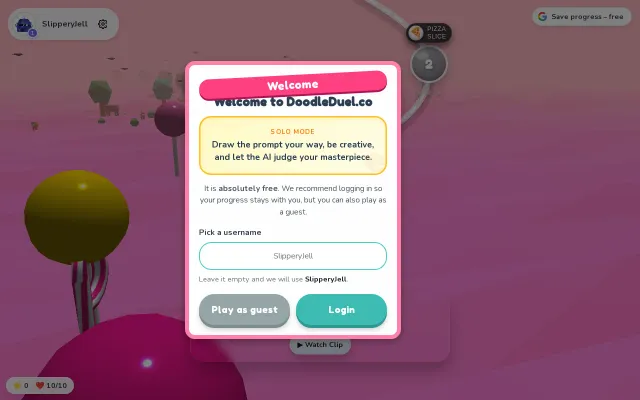
AI vision judging adds a funny twist to the standard Pictionary-style formula.