AI/ML●●Solid
An API that catches what your LLM confidently got wrong
Six specialized endpoints including causality graphs for grounding AI outputs.
SlickSolve My Problem
hanwoo
521mo ago

Cross-vendor verification catches hallucinations when LangSmith and Arize exist.
Enterprise teams deploying LLMs in regulated domains
LangSmith · Arize · Braintrust
Six specialized endpoints including causality graphs for grounding AI outputs.
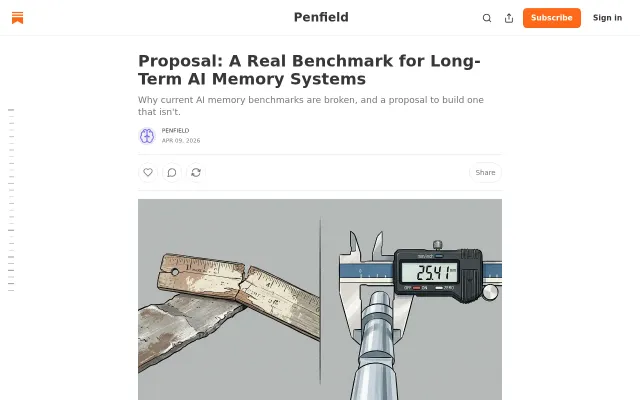
Audited LoCoMo and found 6.4% of answer keys are wrong—benchmarks are broken.
Personal framework for one AI assistant — clever but too narrow to generalize.
Scans ChatGPT and Claude to catch lies about your SaaS pricing.
Agent found real container escape via genome.json manipulation; reframed how to think about hostile code.
Schema-valid evidence packs for AI agents when generic evals miss domain nuance.