Infrastructure●●Solid
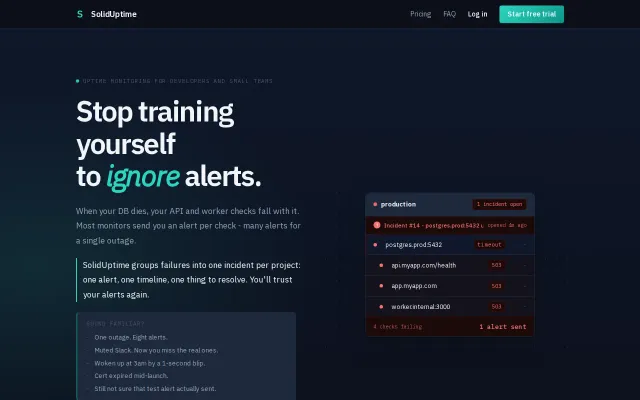
SolidUptime – Uptime monitoring with incident grouping (free, no CC)
Groups failing checks into single incidents so you stop ignoring alerts.
Solve My ProblemSlick
Abs46
212mo ago
Open-source, local-first, read-only AI SRE: clusters alert storms, investigates root cause over your live systems, proposes human-gated fixes.
Read-only AI agent architecture prevents production accidents during incident response.
SREs, DevOps engineers, platform teams
Datadog · PagerDuty · FireHydrant
the reason for this weekend project is that we had a kubernetes upgrade that went wrong, and at some point a rollback wasn't possible anymore, so it had to be fixed live during the night while several problems came together. We run a lot of different systems, on-prem and several Kubernetes clusters, and in a situation like that you spend most of the time just figuring out what is actually broken and where.
So i thought that it would be pretty cool to have eyes in the dark in each system that can talk to your "brain".
so the idea is to put a baby owl into each environment. Each owl runs where the systems live, keeps that environment's credentials local, and only dials outbound to a central brain, so there is no inbound hole into prod. It exposes a set of read-only skills, and the agent uses them to gather evidence and form a root-cause hypothesis, so the on-call engineer starts with a head start instead of from zero.
read-only for now, i don't trust it near prod yet and honestly neither should you.
llocal-first for easy self-hosting and to keep credentials on your side. the clustering and recommendations run fully offline with no llm at all. the agent needs a tool-calling llm, you can point it at a remote one, or self-host one (ollama etc.) if you want to stay fully offline.
for non selfhosters: before every remote llm call, nightwatch strips real secrets (unrestorable) and swaps identifiers like ips, hostnames and paths for reversible placeholders, so the model only sees masked data while real values are restored only in the proposed commands and tool calls
Would love if you try it in your Systems
Groups failing checks into single incidents so you stop ignoring alerts.
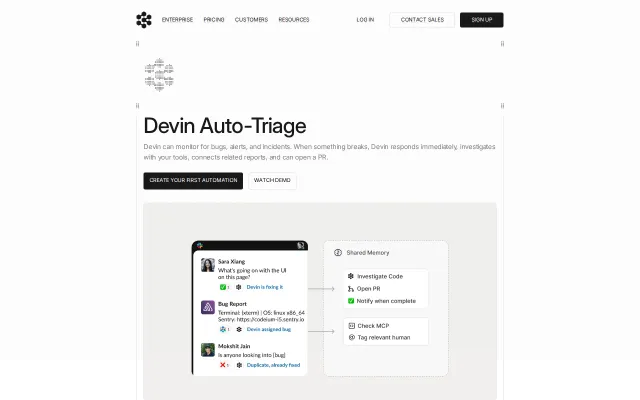
The project converts on-call triage into a hypothesis-driven agent that forms and prunes hypotheses, fetches evidence from CloudWatch/Kubernetes and your runbooks, and surfaces an investigation plus approval-gated remediation steps. I like the npx demo, read-only-by-default K8s stance, and built-in audit trail; the obvious caveat is its dependence on proprietary LLM keys and the ops work needed before trusting any mutating actions in production.
Auto-triage is a classic sales demo feature wrapped in a proprietary black box.
Hypothesis-pruning incident agent with approval gates beats chaos engineering explorers.
Hypothesis-driven SRE agent with memory—read-only safety and real-world incident tooling.
Claude finds hidden performance bugs in telemetry via natural language — but it's an MCP wrapper.
![I challenged an LLM to find a hidden problem in my telemetry data [video]](/screenshots/47159240_thumb.webp)