Developer Tools●●●Banger
AgentReady – Drop-in proxy that cuts LLM token costs 40-60%
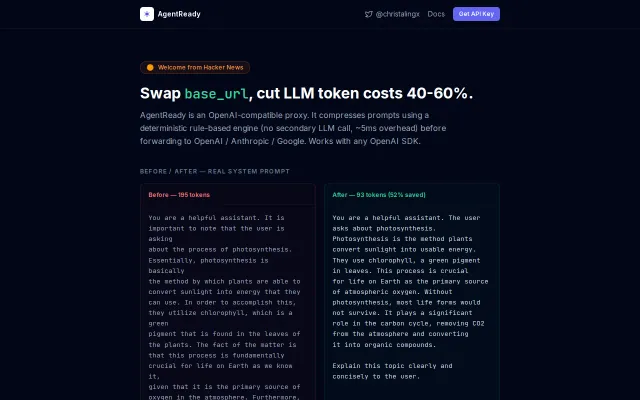
Drop-in proxy that cuts GPT token costs 40-60% without changing app code.
Ship ItSolve My ProblemSlick
christalingx
8134mo ago
OpenAI SDK calls Claude through one proxy with conformance-tested wire translation.
Backend developers using LLM APIs in production
Litellm · Portkey · Helicone
Drop-in proxy that cuts GPT token costs 40-60% without changing app code.
Wire-protocol proxy masks PHI before cloud, restores locally—genuine HIPAA compliance.
Runs as a single binary with embedded SQLite and zero-config start, acting as a transparent, provider-agnostic proxy that logs model, tokens, latency, cost and API key hashes while leaving full body capture opt-in. It also proxies streaming responses in real time and exposes stable JSON analytics endpoints — a practical, instrumentable way to get reproducible, audit-ready traces for real LLM traffic, though long-term value depends on how it handles provider edge-cases and SDK compatibility.
Multi-provider cost dashboard when LangFuse and Helicone already do this.
If you're burning through Claude/OpenAI credits, this is a low-friction stopgap: it classifies prompts in ~10ms and routes trivial tasks to cheaper/local models while reserving premium APIs for complex work. The agentic-task detection, reasoning-aware routing, session pinning and context-window fallback are practical touches that avoid mid-thread model bouncing and 429 failures. It isn't reinventing the space (OpenRouter and others exist), but it's focused on real-world cost tradeoffs and drop-in compatibility.
Independent billing receipts when OpenAI and Anthropic grade their own invoices.