AI/ML●Mid
Building a SQL analyst agent from scratch
Focuses on iterative schema exploration, but LangChain and Vanna already solve this.
Ship It
ramin2nt2
603mo ago

In-browser SQLite with LLM sanitization when chat-with-data tools already exist.
Data analysts and developers concerned about data privacy
Cursor · Sourcegraph Cody · Vanna AI
You ask a question, agents produce multiple SQL queries to in-browser sqlite, never seeing results, and write dashboard configuration code. The data you analyze will be indexed with a local semantic index (embeddings generation + sqlite vector search fully local).
Next, sandboxed QuickJS runs this code to produce rich dashboards directly in your browser, no backend attached. This is a fully frontend app (except OpenRouter or other remote LLM).
All data sent to LLM's is heavily sanitized and obfuscated at several points. The remote LLM never sees the contents of data it analyzes. Why does it exist - I started this is a testbed for my local-first AI projects, agentic workflows and contextual data analysis experiments.
It grew into a tool I use daily for quick and dirty data analytics when I don't want to waste time debugging SQL or building charts for simple data questions, when I literally need an answer under 10s.
I also don't like the idea of sharing random data in Claude/ChatGPT chat, neither uploading any work-related datasets to them. Plus they both often choke on tiny 100k rows data.
Fully open-sourced under MIT https://github.com/eatmydata-org/eatmydata, run it yourself it's a static web app.
What's in the box:
- SQLite OPFS adapted from wa-sqlite, data queried only locally;
- TurboQuant semantic indexing extension for sqlite (MIT-licensed);
- Quantized PII detection and embedding generation models straight in browser;
- NER and embeddings inference engines in zero-dependency C and wasm-simd128 optimizations (1.7x faster and 38x lighter binary compare to onnxruntime);
- QuickJS sandbox for AI-generated code;
- Orchestrator <-> SQL Planner <-> Coder agent loop that build SQL and dashboards from user query;
- Apache ECharts for dashboards;
- Fork of xslx Community edition to support styles (missing in OSS version upstream).
Hope it'll be useful to anyone who is interested in local-first stuff.
Focuses on iterative schema exploration, but LangChain and Vanna already solve this.
Offline SQL queries against AWS inventory with zero-dependency natural language.
Exports straight from .sql to XLSX/CSV with sensible niceties — template-aware Excel exports, CSV profiles (delimiter/encoding/quoting/date formats), retry handling for deadlocks, and a demo SQLite so you can try it immediately. It’s not trying to be a BI stack; it’s focused on the boring but painful task of re-running queries and producing predictable spreadsheets. If you want multi-step ETL, dashboards, or semantic modeling, this isn’t it — but for quick, repeatable reports it’s pragmatic and usable out of the box.
SQL queries on CSV streams—instant, zero-setup alternative to awk and sqlite3 boilerplate.
Searchable terminal history with output capture beats ctrl+R for debugging, local or Anthropic-powered.
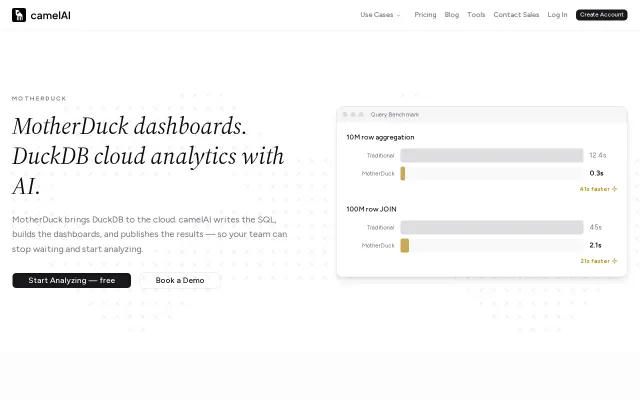
Generates native DuckDB SQL for MotherDuck instead of generic dialect.