Developer Tools●●●Banger
udoc. Dependency-free document extraction in Rust
Pure Rust parsers for legacy Office formats with zero external dependencies.
WizardryBig Brain
newelh
5124d ago
Another AI document summarizer with pretty graphs in a crowded field.
Researchers, students, journalists analyzing dense documents
Heptabase · Scrintal · Obsidian with AI plugins
Pure Rust parsers for legacy Office formats with zero external dependencies.
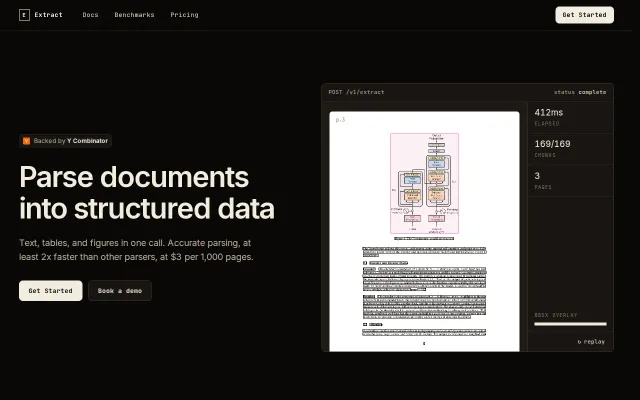
Per-span confidence scores let you review uncertain OCR before trusting 200k-page runs.
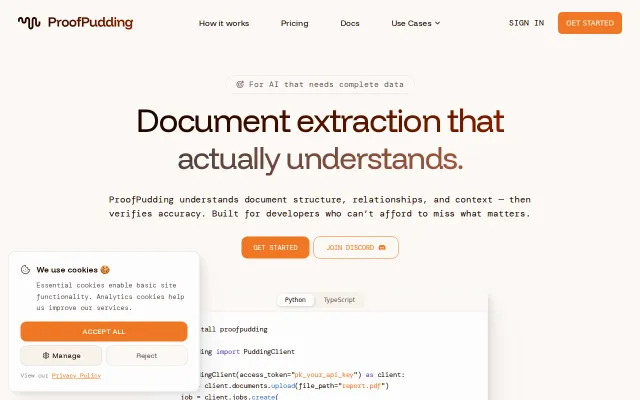
ProofPudding returns extraction results with explicit links back to the exact page and source text, supports native and scanned PDFs plus DOCX/images, and ships Python/TypeScript SDKs — handy for agents that need auditable facts. It’s a pragmatic product (per-extraction pricing and confidence scores are nice), but the market is crowded; I want clarity on underlying models, real-world accuracy numbers, and how it compares to Document AI/Textract in edge cases.
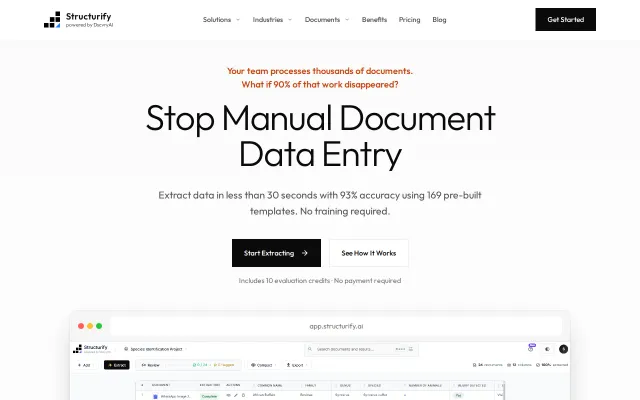
93% accuracy document extraction, but remove.bg-style competition already exists.
Extracts tracked changes and comment threads when most DOCX parsers only grab text.
Automates EU AI Act Annex IV dossiers by parsing your Python codebase for evidence.