Developer Tools●●Solid

Slopsome – a VRAM fit calculator and tok/s database for local LLMs
VRAM calculator with crowd-sourced tok/s benchmarks when model cards already exist.
Niche GemSolve My Problem
NexAIGuy
306d ago
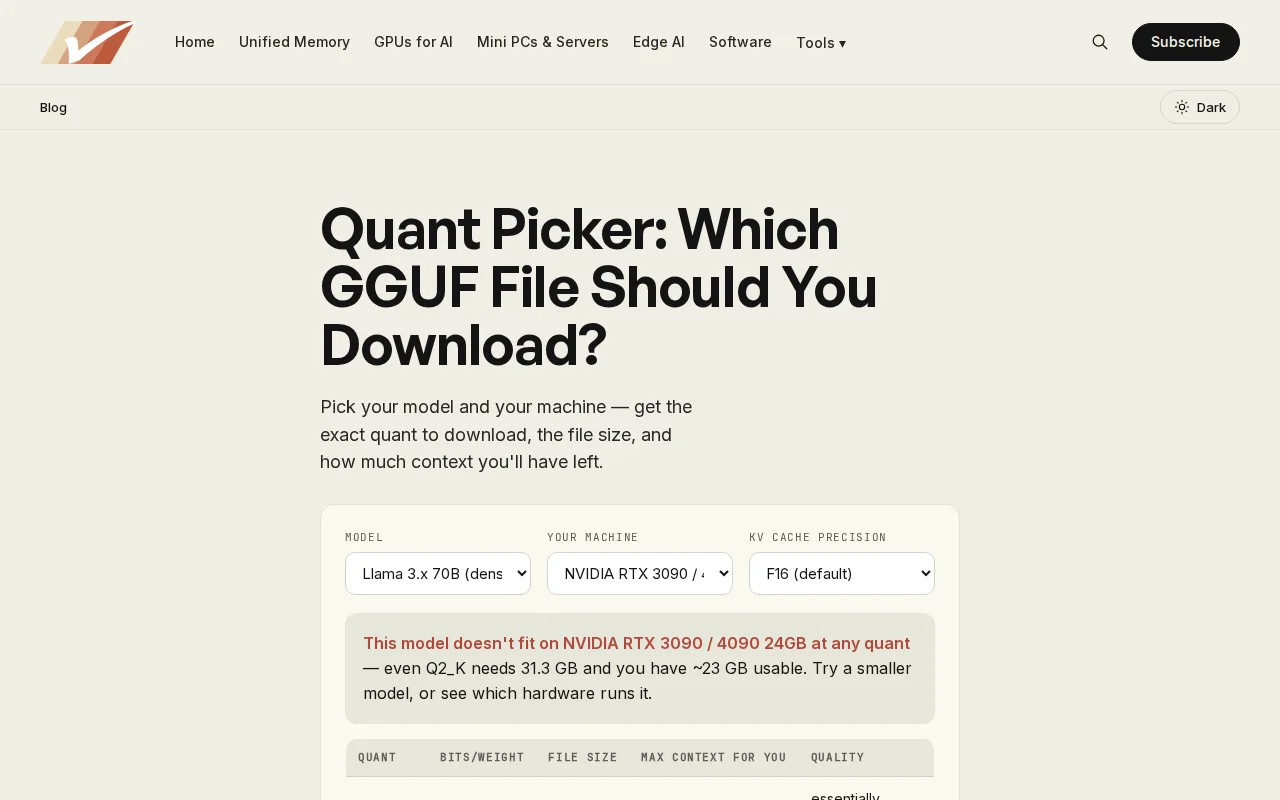
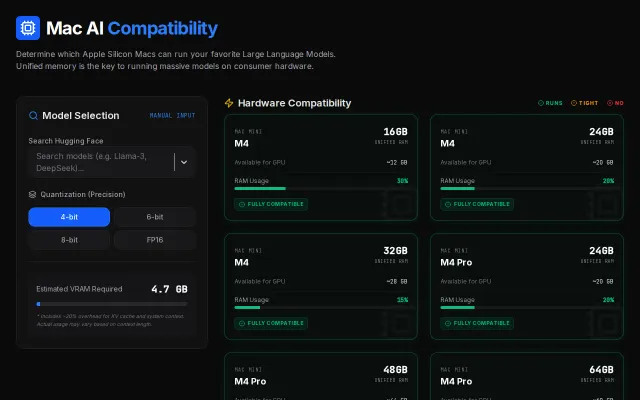
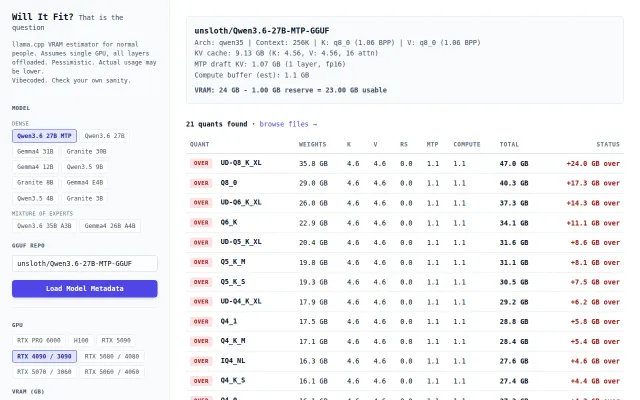
Finally answers the GGUF quant question everyone asks in Discord.
Local LLM runners and hobbyists
VRAM calculator with crowd-sourced tok/s benchmarks when model cards already exist.
Clean hardware-model compatibility checker, but solves a narrow, one-time lookup problem.
Ollama and llama.cpp server already do this with more maturity and model support.
Useful tutorial, but llama.cpp docs and Ollama already cover most of this.
Opinionated llama.cpp VRAM calculator that outputs ready-to-run server commands.
The project nails a real pain: instead of guessing whether a 7B or 13B model will fit, llmfit inspects your system and ranks 94 models by fit, speed, context and quality, even recommending quantization and run modes and supporting multi‑GPU and MoE setups. The combo of an installable binary, interactive TUI for quick browsing and JSON output for automation makes it immediately useful; just remember its suggestions are heuristics — you’ll still want to validate edge cases with a real run.