AI/ML●●●Banger
I made a small helper for checking model-graded answers
Structurally verifies LLM judge reasoning instead of paying for a second model check.
Big BrainSolve My ProblemDark Horse
ML0037
204d ago
A memory layer that tracks evidence, claims, and decisions to make multi-turn LLM judges and reviewer agents more inspectable and stable.
Flags LLM judge verdicts unsupported by evidence without needing a second model.
AI researchers and engineers running LLM evaluation pipelines
Arize Phoenix · LangSmith · Braintrust
TL;DR: it breaks an LLM judge run into claims->evidence->verdicts and flags when a verdict is not supported by the evidence, so i can check it manually
Structurally verifies LLM judge reasoning instead of paying for a second model check.
Useful utility but checking HuggingFace cards directly works too.
One-line wrapping eliminates invisible LLM spend; real cost forecasting and model recommendations.
Multi-agent fact-checking loop, but RAG hallucination fixes are table stakes now.
SQLAlchemy migration tool, but Alembic already dominates this space completely.
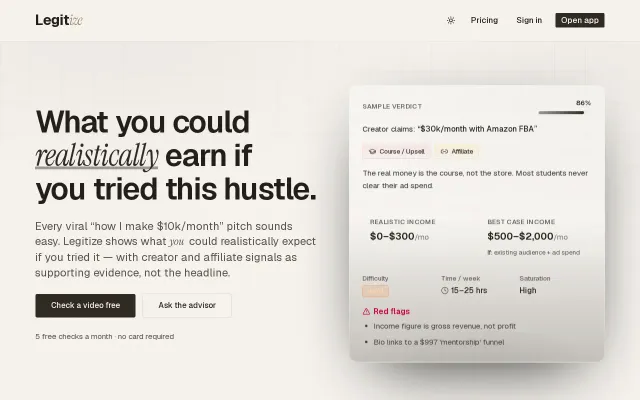
Creator incentive classification beats generic fact-checkers at spotting course scams.