Data●●Solid
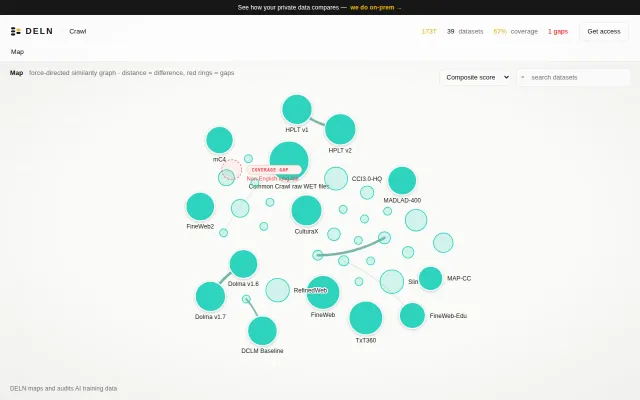
DELN – An interactive atlas of AI training datasets
Force-directed dataset atlas with gap detection Hugging Face doesn't offer.
Niche GemBig Brain
yshunnar
2012h ago
Cross-source dedup with pgvector at 0.92 cutoff beats manual scraping workflows.
ML researchers, data scientists building fine-tuning datasets
HuggingFace Datasets · Semantic Scholar API · Papers With Code
Force-directed dataset atlas with gap detection Hugging Face doesn't offer.
LLM-based cleaning operators beat regex pipelines for messy text data.
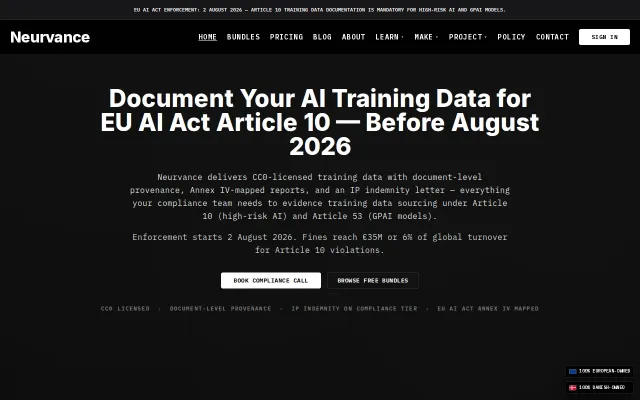
CC0 data bundles with Annex IV reports for EU AI Act compliance before August 2026.
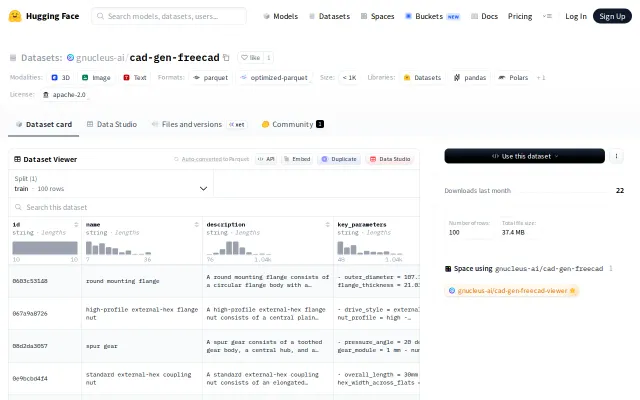
Parameterized FreeCAD dataset fills a critical gap for training generative CAD models.
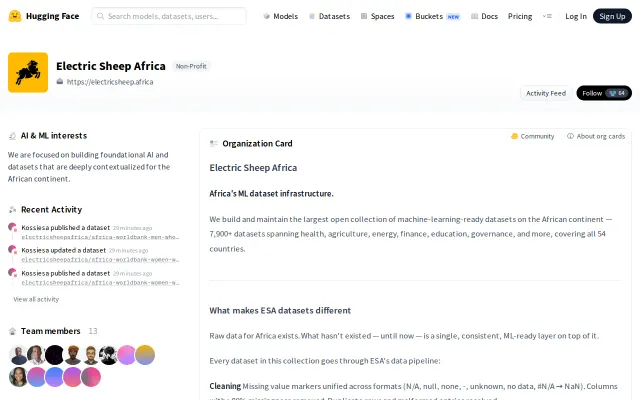
7,900+ harmonized African datasets with BibTeX provenance and one-line dataset library loading.
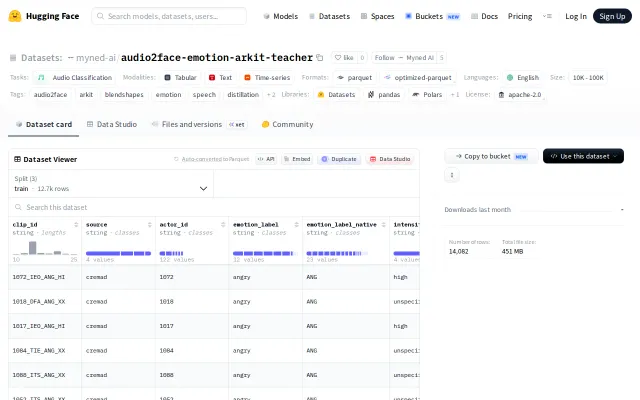
Yet another Hugging Face dataset in a sea of thousands.