Developer Tools●●Solid
glide – LLM cascade proxy, auto-switches models before timeout
TTFT-aware model fallback—avoids timeouts by hedging between Opus, Sonnet, Haiku automatically.
Solve My ProblemNiche Gem
phanisaimuni116
113mo ago
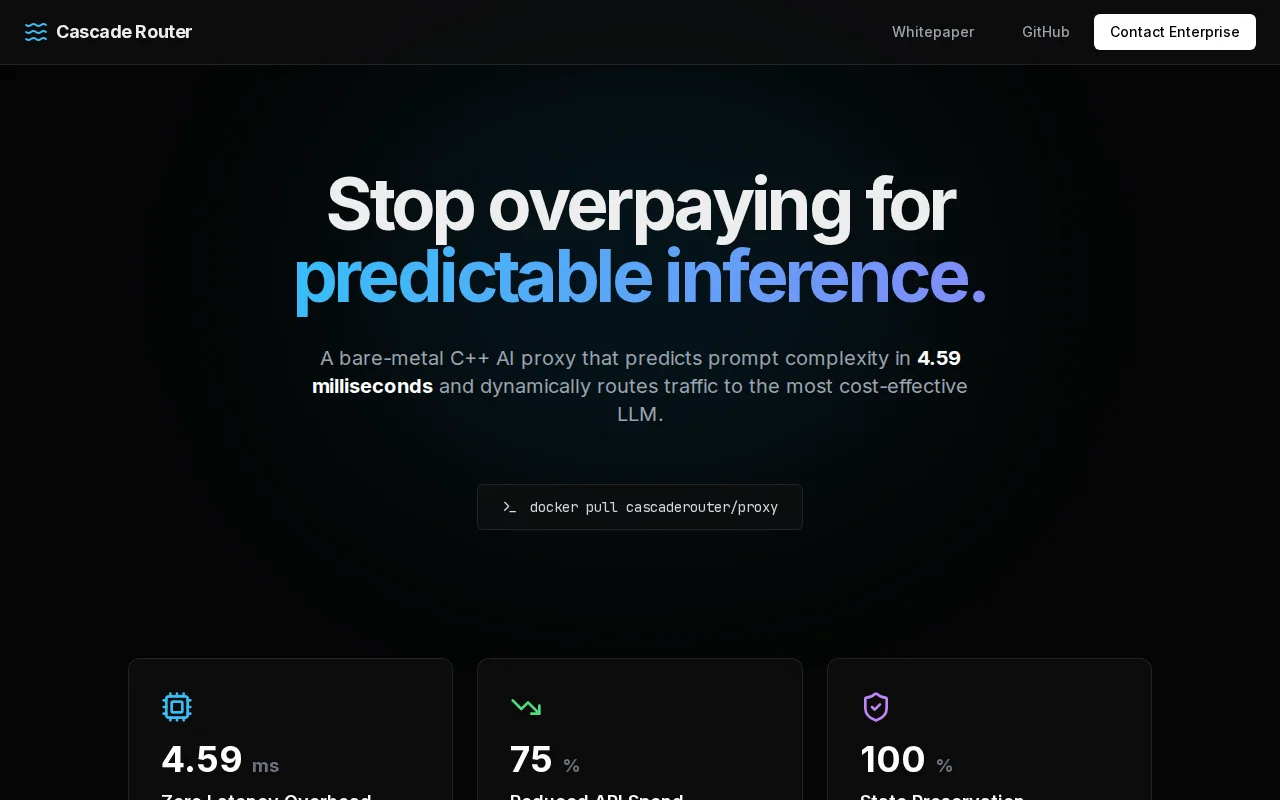
ONNX embeddings predict prompt complexity before routing—LiteLLM does this with rules.
Engineering teams with significant LLM API spend
LiteLLM · Portkey.ai · Helicone
TTFT-aware model fallback—avoids timeouts by hedging between Opus, Sonnet, Haiku automatically.
Wire-protocol circuit breaker for agents when LangSmith costs too much.
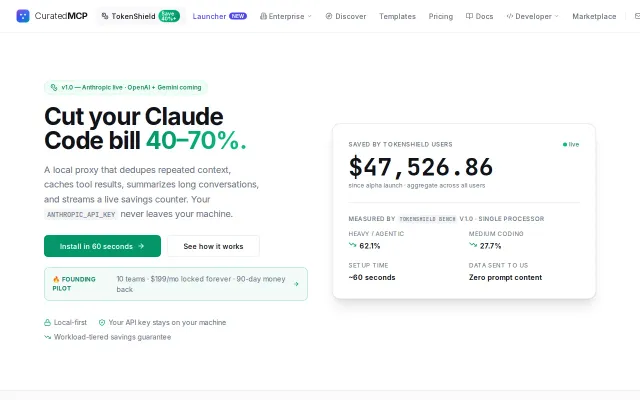
Six optimization layers slash Claude Code bills while keeping your API key local.
XDP drops packets before the kernel stack while nftables handles stateful logic.
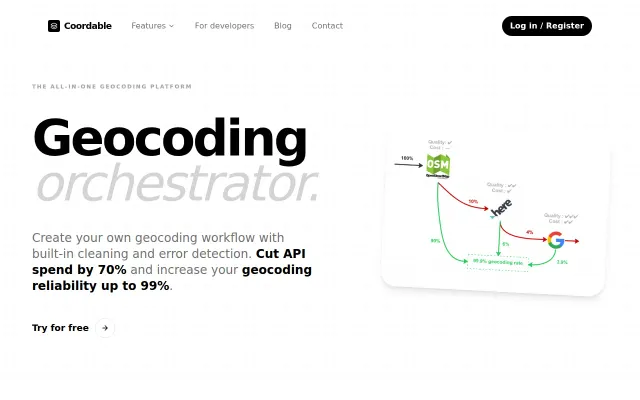
LLM address validation catches silent errors providers confidently return wrong.
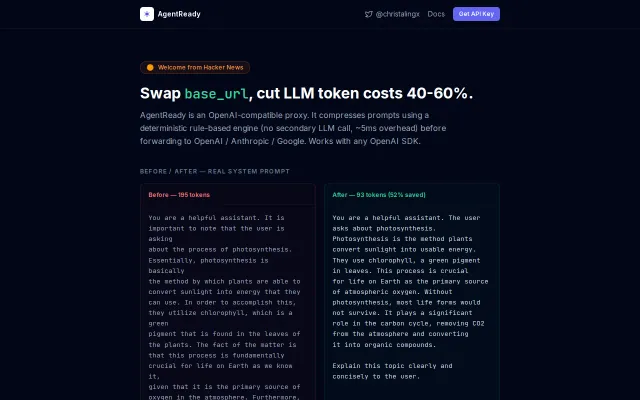
Drop-in proxy that cuts GPT token costs 40-60% without changing app code.