AI/ML●Mid
I reduced LLM inference GPU calls by 94% using semantic routing
94% GPU reduction claim needs verifiable benchmarks to stand out.
Bold BetShip It
kanacki
2124d ago
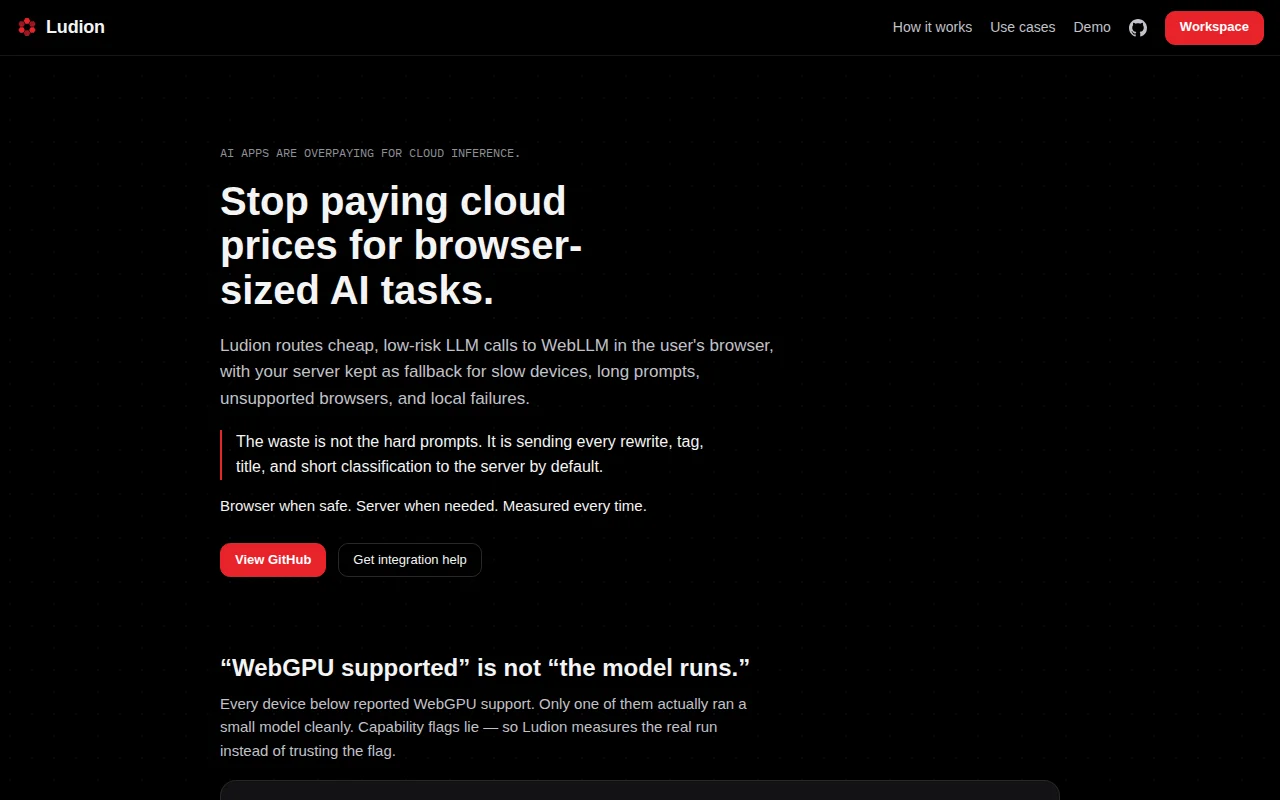
Measures actual WebGPU runs instead of trusting capability flags that lie.
Developers building AI apps who want to reduce cloud inference costs
WebLLM · Transformers.js
94% GPU reduction claim needs verifiable benchmarks to stand out.
Routes LLM requests to GPUs with cached KV prefixes, skipping redundant prefill computation.
Zero-trust networking via zrok beats LiteLLM when your GPUs sit behind NAT.
Sequential-dispatch methodology corrects 20x overestimation in prior WebGPU benchmarks.
Mitmproxy integration shows raw HTTP when LangSmith only shows parsed traces.
Explicit kernel control over TVM-style black boxes, but benchmarks show mixed wins vs Transformers.js.

