AI/ML●Mid
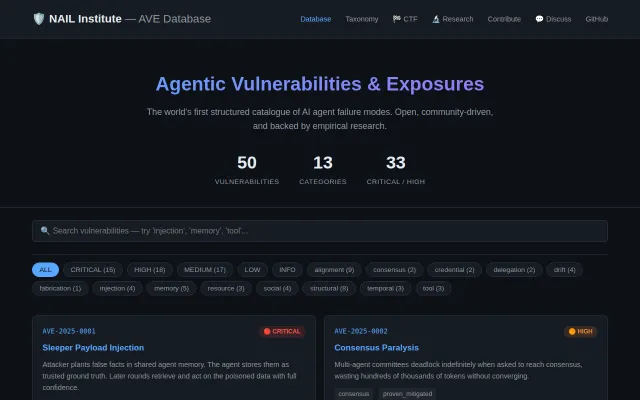
Named failure modes that stop AI agents from cutting corners
Named failure modes for AI agents, but it's markdown files—not an actual tool or implementation.
Big BrainNiche Gem
travisdrake
103mo ago
An open benchmark for the failure modes of agent memory systems: retraction, collision, recall, conflict. Offline, zero-dependency, reproducible.
Shows retrieval metrics lie—answer correctness ranges from 23% to 92% across identical scores.
AI agent developers, ML engineers building memory systems, researchers
HELM · AgentBench · GAIA
Named failure modes for AI agents, but it's markdown files—not an actual tool or implementation.
First structured CVE-style database for AI agent failures—nobody else is doing this.
World record on LongMemEval beats PwC Chronos, built solo in 16 days.
First OWASP-backed security layer for ASI06 memory poisoning in agentic AI.
Synthetic e-commerce site with failure injection beats flaky live-site testing.
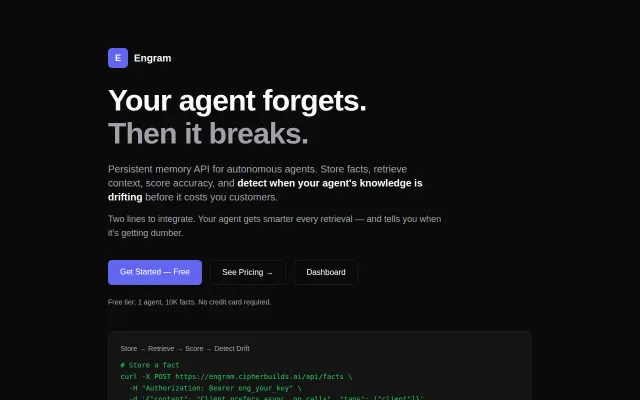
Mem0 stores facts, but Engram detects when they go stale and break your agent.