Infrastructure●●Solid
AI Cost Firewall – OpenAI-compatible gateway with semantic caching
LLM gateway with Redis + Qdrant caching, but LiteLLM does this.
SlickShip It
vcaluser
113mo ago
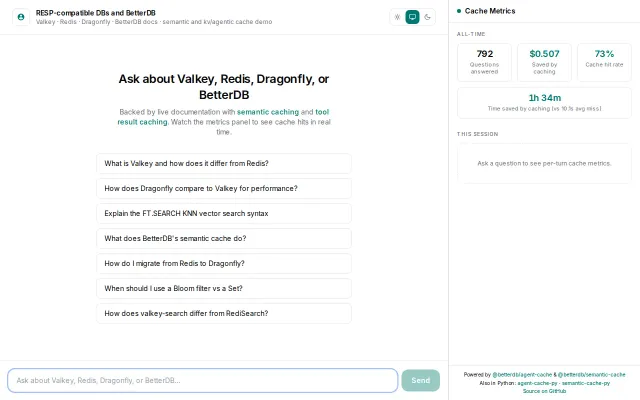
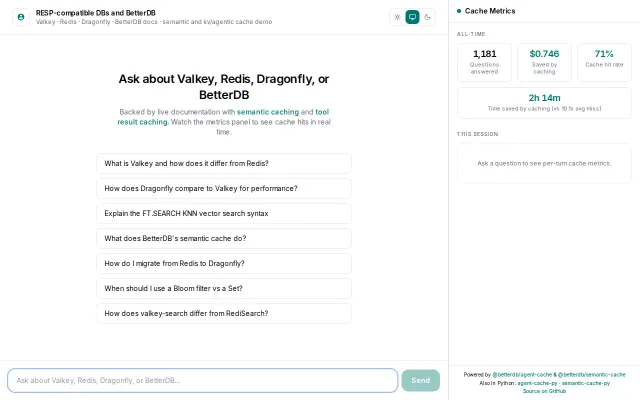
Transparent, transport-layer semantic cache for LLM API calls, powered by Redis 8 Vector Sets.
Transport-layer interception beats GPTCache with zero code changes required.
Developers building LLM-powered applications with high-volume repetitive queries
GPTCache · CacheLLM · LLMCache
LLM gateway with Redis + Qdrant caching, but LiteLLM does this.
Semantic caching without a vector DB—just swap your base URL.
Semantic caching proxy when Helicone and Portkey already dominate.
Two-tier caching saves real money, shown live on the dashboard.
Semantic caching for LLM APIs exists (Anthropic prompt caching, Langchain, Miniplex, vLLM); gateway routing is table stakes.
Tool result caching for agents when GPTCache and LangChain already do semantic caching.