Data●Mid
RAG-Ready Extractor – Structure-aware ingestion with semantic scoring
Noise-filtered PDF/web extraction for RAG, but already solved by Jina, Firecrawl.
Solve My Problem
cddIT
313mo ago
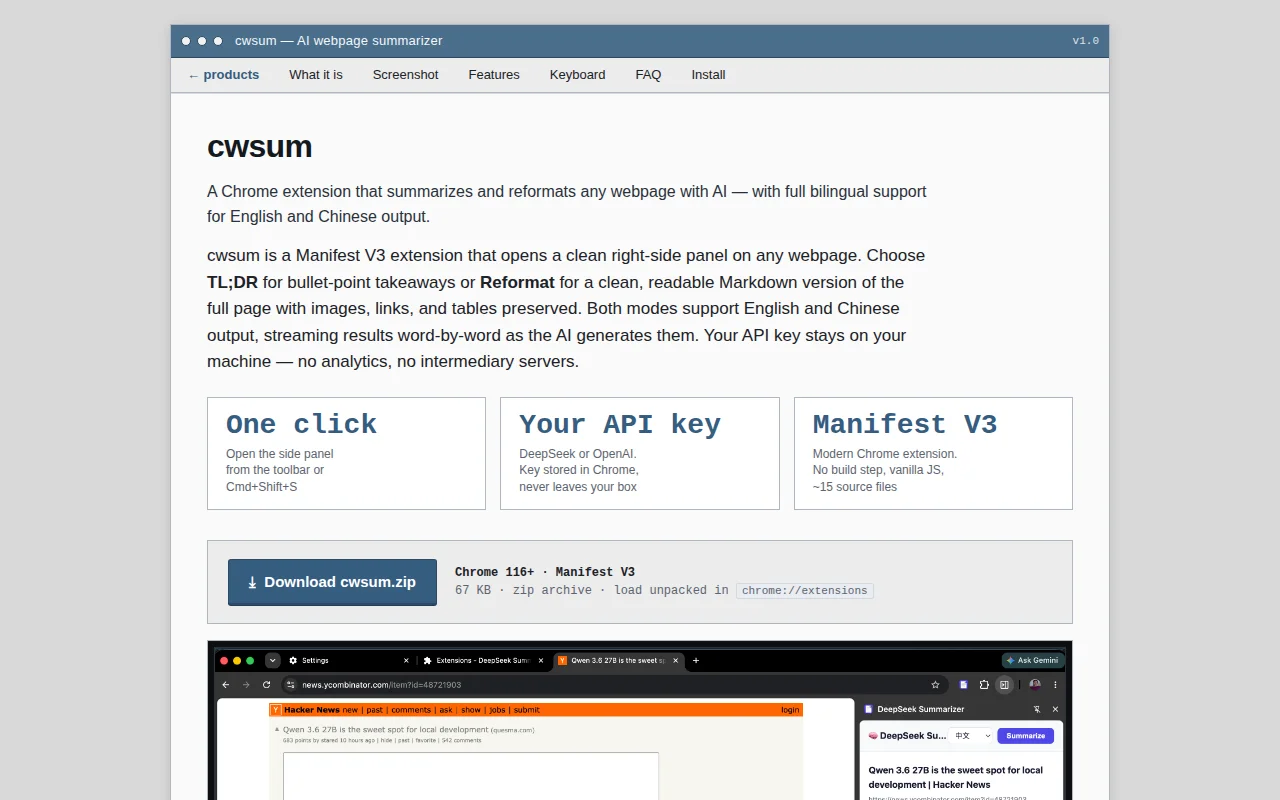
Yet another AI webpage summarizer when Mercury Reader already exists.
Chrome users who read lots of web articles
Mercury Reader · Reader Mode · Jina AI Reader
Another cool thing is since it's based on LLM, so I could reformat the page into different language such as Chinese.
Enjoy
Noise-filtered PDF/web extraction for RAG, but already solved by Jina, Firecrawl.
Fact-checks claims against live web sources using a tiny 0.8B model on CPU.
Product page returns 404 in a category already solved by Reader mode and extensions.
Free coding agent when Cursor and Continue already dominate the space.
Nice, focused product: site-specific extraction rules (CSS selectors/metadata overrides), edge-first delivery (<500ms p99) and SDKs for Node/Python make it quick to drop into an LLM pipeline and claim 40–60% token savings. That said, HTML→Markdown is a crowded niche (Pandoc, Jina, Firecrawl and dozens of scrapers already exist), so Klovr needs clearer differentiation — e.g. demonstrable extraction accuracy, enterprise-grade rule sharing, or unique model-aware trimming — to move beyond 'handy utility'.
HN summarizer when RSS readers and newsletters already do this.