Developer Tools●Mid
LLM Gateway – Simple API format converter for LLM providers
LiteLLM already does this with more providers, more features, and way more maturity.
Ship It
modinfo
203mo ago
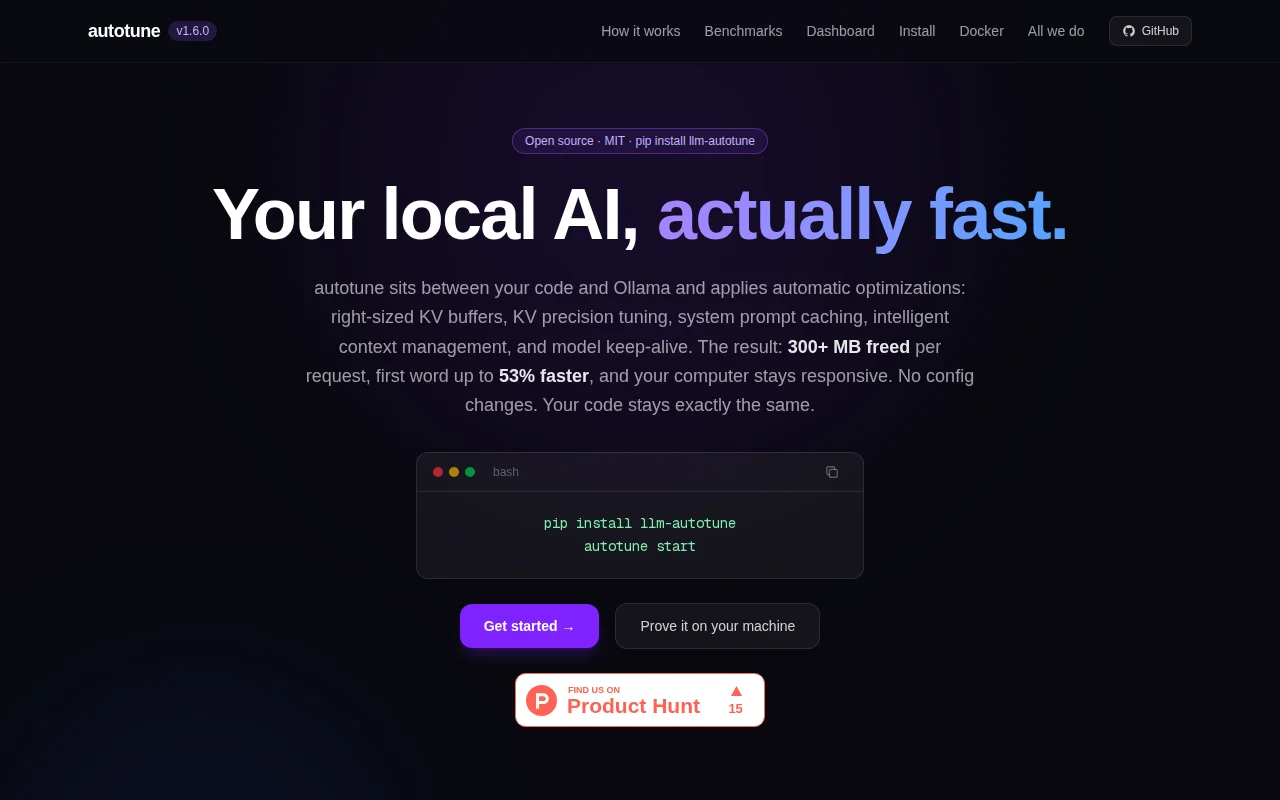
Dynamic KV cache sizing beats Ollama's wasteful 4096-token default allocation.
Developers running local LLMs with Ollama
Ollama · vLLM · llama.cpp
Tracks your resource usage in real-time and adjusts how the model runs so that it works perfectly on your device.
Implements KV cache sizing, prefix caching, live RAM pressure management, context trimming, KV quantization, and more.
Built a ton of features
LiteLLM already does this with more providers, more features, and way more maturity.
TTFT-aware model fallback—avoids timeouts by hedging between Opus, Sonnet, Haiku automatically.
Claims 4.2x Ollama speed with 0.08s cached TTFT on Apple Silicon.
Another AI security wrapper in a crowded market, but agent-side integration is interesting.
Not a proxy — optimizes Anthropic and OpenAI caching without adding latency or seeing your data.
They stopped pretending chunking at arbitrary byte offsets was fine and instead scan once to build message boundaries, then binary-search for clean split points — that simple change eliminates the OOM-by-design scenario. Couple that with SIMD-aware prefetch tuning (different distances for AVX2 vs AVX-512) and you get practical microarch-aware engineering, not just benchmark stunts; I want this shipped as a library or tool so other firms can stop reinventing the same footguns.