AI/ML●●Solid
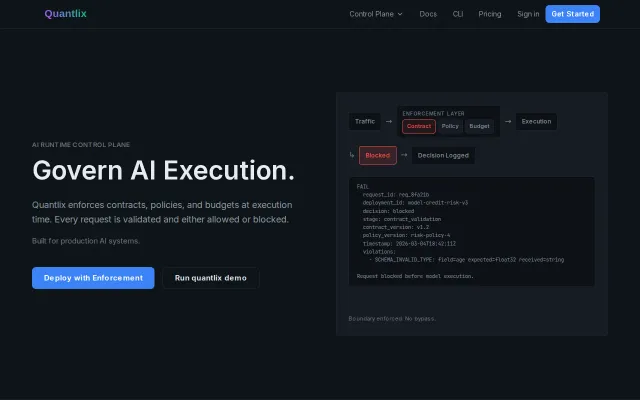
Quantlix – Runtime enforcement layer for AI systems
Schema + policy + budget enforcement at execution boundary before model hits.
Big BrainSolve My Problem
jensenjesper
104mo ago
Engineering architecture for runtime state modulation in Large Language Models.
Current LLMs are statically frozen after RLHF. The Generator runs, but the constraints (Reward Model logic) are dead. We are forcing a corpse to act smart via Prompts.
2. The Architecture:
I propose decoupling the "Constraint" from the "Generator". Introducing a Modulator – a micro-component that doesn't generate text but controls runtime states (KV Cache, Attention Budgets, Context Windows).
3. The Hypothesis:
If constraints persist in the runtime state ( + , - , 0 ), the Generator stops "remembering" and starts "adapting". This isn't about higher scores; it's about a different physics of inference.
Schema + policy + budget enforcement at execution boundary before model hits.
Heuristic signals triage agent traces 1.52x more efficiently than random sampling.
Stateless Go proxy routes LLM requests by model name to vLLM backends.
Frozen models gain reflexive awareness via lightweight hidden state intervention taps.
LLM never touches the substrate, deterministic layer handles all execution and validation.
VERONICA puts an enforcement shim between your agent and the model so you can halt costly spirals before a request hits the provider — it natively exposes hard budget enforcement, circuit breakers, retry containment and degradation levels. The README + runnable runaway-loop demo make the failure mode concrete and the API (BudgetEnforcer, RuntimeContext, BudgetExceeded) is small and practical. I'd like to see richer observability/adapter docs for common agent frameworks, but as an enforcement-first primitive this is a clever, useful tool.