Infrastructure●●Solid
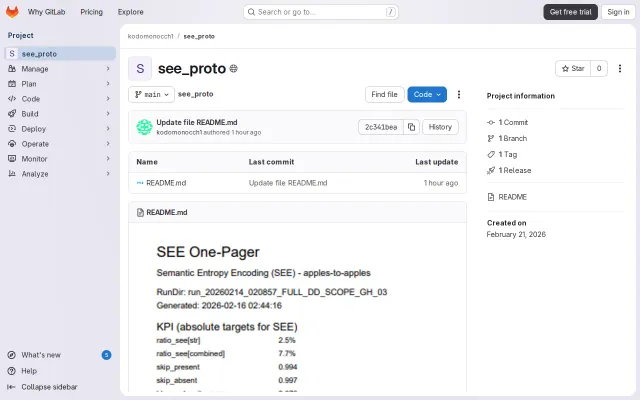
See – searchable JSON compression (offline 10-min demo)
Schema-aware JSON compression stays searchable; reaches 7.7% vs Zstd's 13.7%.
Big BrainWizardry
Tetsuro
504mo ago
This is kind of the worst possible side project, because it sounds very unimpressive but it's actually pretty tricky. You would think, as I did, that because the American populace is one of the most heavily surveyed, most reliably censused people on earth, that generating demographically and statistically accurate random Americans would be fairly easy. For one or two variables, that's true. We have extremely good data on, for instance, the number of men versus the number of women in the country. But combining variables gets much harder because of the way probabilities intersect. For example, ~30% of people are Democrats and ~10% of people are from California, but substantially more than 30% * 10% of people are California Democrats because P(Democrat | Californian) is higher than P(Democrat). So getting in age, gender, state, race, and political affiliation all based on good-quality data without making independence assumptions was a headache. This site also includes U.S. territories, which also made the project more difficult since they have more patchwork data sources. Names and exact geographic locations are also generated, but these use more back-of-the-envelope math and approximations that are not supposed to be 100% demographically accurate--I included them so that the the 'people' generated would have more personality and the whole thing would work better visually.
Schema-aware JSON compression stays searchable; reaches 7.7% vs Zstd's 13.7%.
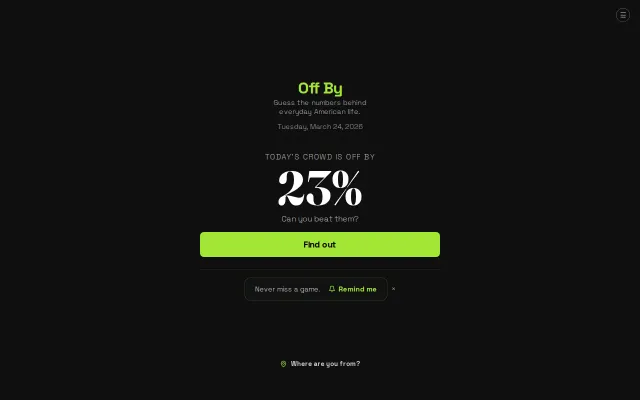
Wordle for economic data—fun for a week, then you've seen all the surprises.
Beats Zstd-19 on size, keeps JSON queryable without external indexes.
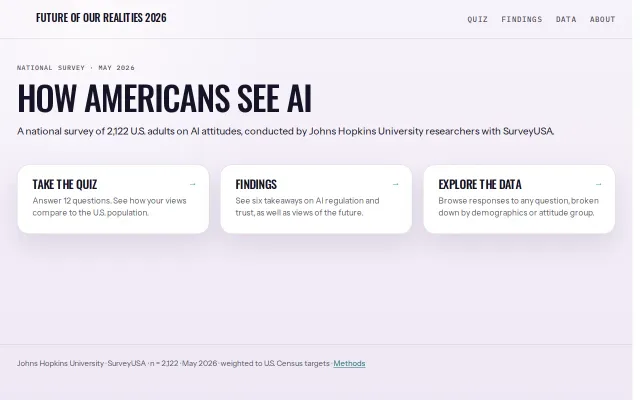
Real survey data with demographic breakdowns, but it's just charts and a quiz.
Double-blind randomness via player commit, server secret, time-locked Drand. Technically sound but niche.
Turns idle Macs into Jellyfin previews, skipping intros automatically.